教師なし学習 (Unsupervised learning)
教師なし学習は、教師ラベルが与えられていないデータの分析方法である。Unsupervisedタブでは次に示した主な教師なしの方法を実装している。ここでは、川端康成と三島由紀夫の小説を例として各手法を説明する。
主成分分析 (Principle Components Analysis)
主成分分析は、情報の損失をできる限りすくないように高次元データを低次元に圧縮する教師なしの方法である。川端康成と三島由紀夫の作品を読み込み、文字bigramを集計し、主成分分析のタグの画面コピーを次に示す。
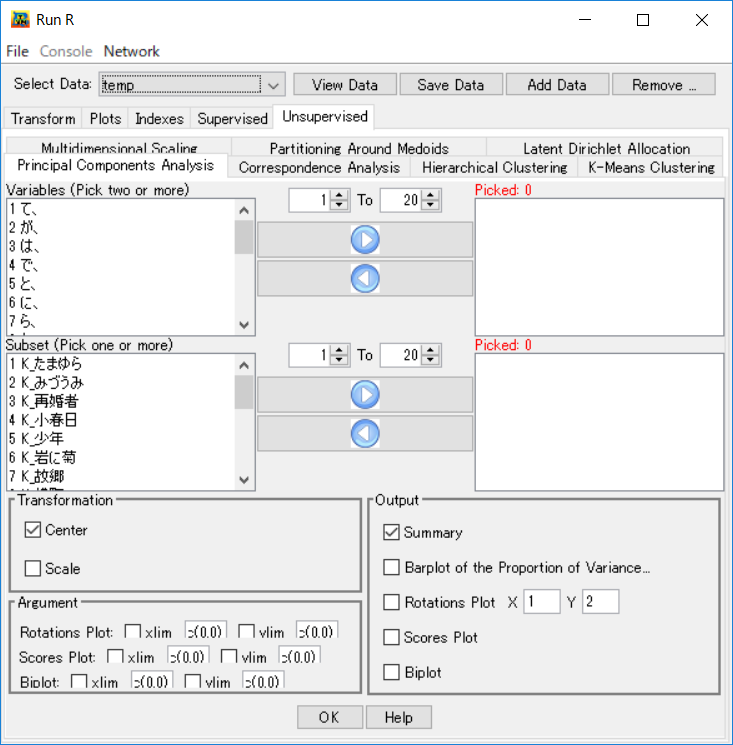
画面上の左側には、変数のリストとテキストのリストが表示されている。主成分分析行うためにはまず用いる変数と用いるテキストを選択し、右側のPickedの窓に取り入れることが必要である。
- 変数と個体の取り入れ
- 分析のオプションを指定する
- 出力のオプションを指定する
- Summaryにはチェックボックスにチェックがついている。この環境で実行すると主成分分析要約(標準偏差、寄与率、累積寄与率)がOUTPUT画面に出力される。
- Barplot of the Proportion of Varianceを選択すると寄与率と累積寄与率の棒グラフが一つグラフ画面として出力される。
- Rotation Plotを選択すると固有ベクトル・主成分の散布図を作成する。Xの窓には横軸に用いる主成分の番号、Yには縦軸に用いる主成分番号を指定する。
- Scores Plotを選択すると主成分の得点の散布図を作成する。横軸と縦軸はRotation Plotと一致する。
- Biplotを選択すると主成分のバイプロットを作成する。
- 出力グラフの調整オプション
一つひとつ選択し矢印で取り入れ、または取り除くことが出来る。すべてを取り入れる場合はマウスポインターを変数あるいはテキスト窓に合わせ、キーボードのCtrl+Aキーを同時に押すとすべて選択され、矢印ボダンで一括取り入れ、取り除くことが出来る。また変数の数を連番で指定し取り込むことも可能である。
MTMineRには、分散共分散行列と相関係数行列を用いる方法が実装されている。デフォルトでは分散共分散行列を用いた主成分分析を行うになる。GUI上のオプション[scale]にチェックを入れると相関係数行列を用いた主成分分析を行う。[center]は主成分得点をセンターリングするオプションである。一般的にはデフォルトの設定のとおりにセンターリンを行う。
GUIの右下側に出力のオプションがある。
出力オプションの左側には出力するグラフの微調整オプションが用意されている。出力されている主成分分析のグラフは、文字列が枠組み線に切られたり、余白が大きいすぎたりする場合がある。その際には、軸の範囲を広めたり、狭めたりすることでグラフの完成度を上げることが出来る。初心者は無視してよい。
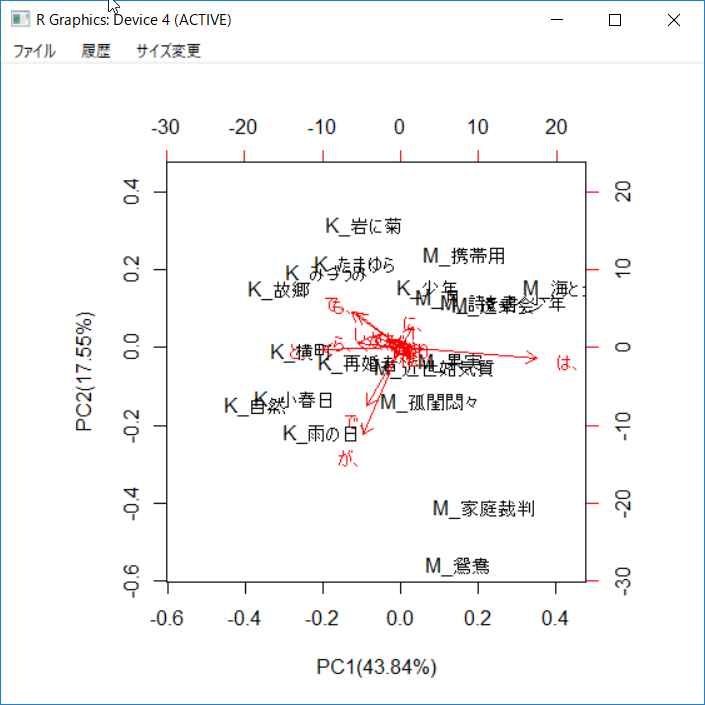
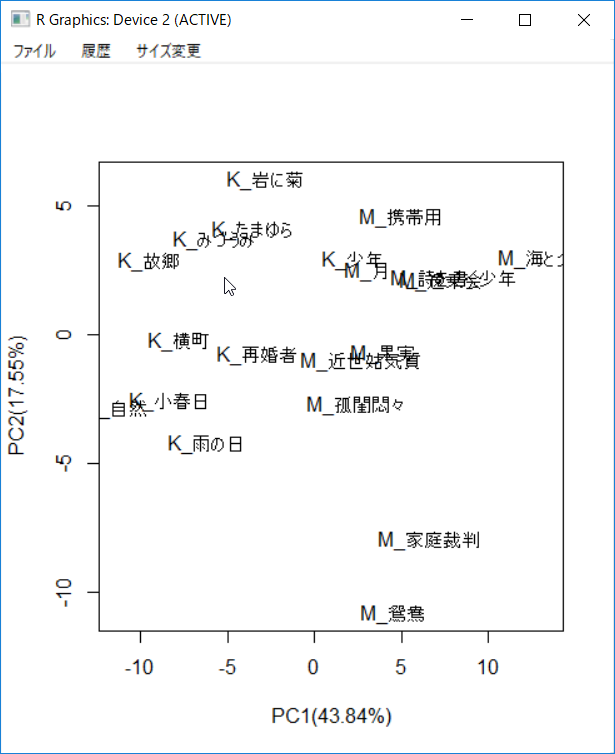
川端康成と三島由紀夫のそれぞれ10編の小説に読点がどの文字の後に打っているかに関するデータを主成分分析GUIに読み込み、GUI上の[OK]ボタンを押すと主成分分析の要約はOUTPUT画面に出力され、第1と第2の主成分に関する二つの散布図と一つのバイプロットが作成される。変数が少ないときには、主成分分析では個体と変数の関係をバイプロットで考察する。出力されているバイプロットに示したように、川端康成の文章は主に左側に集まり、「と、」、「し、」と「も、」の使用率が相対的に高い。テキスト分析の特徴量の次元数がは数百ないし数千に上るときには、バイプロットは大量の変数に覆いつくされて考察できない。この場合score plotで個体の位置関係だけを見る。
 Go To Top
Go To Top
対応分析 (Correspondence Analysis)
対応分析は、高次元データを低次元に圧縮する考え方では主成分分析と同じである。対応分析は、分割表において行の項目と列の項目の相関が最大になるように、行と列の双方を並び替えている。個体を考察する場合Rscore Plot、変数を考察する場合Cscore Plotにチェックを入れる必要がある。
 Go To Top
Go To Top
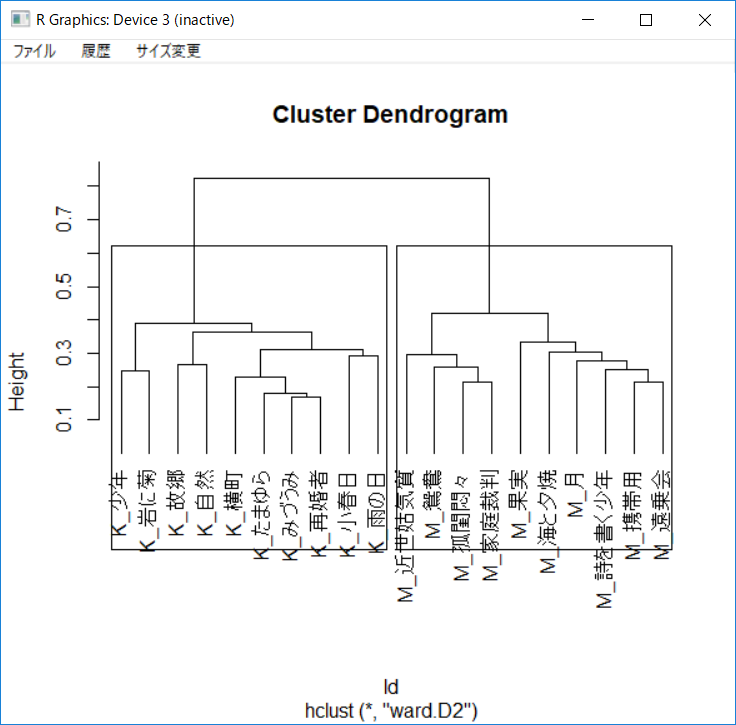
階層的クラスター分析 (Hierarchical Cluster Analysis)
データ分類の手法としてクラスター分析がよく用いられる。クラスター分析は、階層的クラスター分析と非階層的クラスター分析に大別される。階層的クラスター分析は、最も似ている組み合わせから順番にクラスターにしていき、最終的に樹形図(デンドログラム)でデータ間のグルーピングを表す手法である。この手法には(1)元のデータ行列から距離行列を求める(2)クラスターの結合方法を選ぶ(3)コーフエン行列を求める(4)樹形図作成の4つの手順が必要である。距離と結合方法は、それぞれDistance MeasuresとMethodsタブから選択できる。ここでは、クラスター内の分散が最小になるWard法とSKLD距離 (SKLD = $\sqrt{\frac{1}{2}\sum^n_{i=1}\frac{x_i}{x_i+y_i}+\sum^n_{i=1}\frac{y_i}{x_i+y_i}}$)を用いた分析結果を示す。川端康成と三島由紀夫の作品は大きく2つのクラスターに分かれていることが樹形図から見て取れる。

k-means法 (K-Means Clustering)
非階層的クラスター分析の代表的な手法はk-means法である。k-means法のアルゴリズムは次の通りである。(1)初期クラスターの中心を求める(2)すべてのデータと中心との距離を求め、データを距離の最も近いクラスターに分類する。(3)新しいクラスターの中心を求める。(4)(2)と(3)を繰り返し、クラスターの中心が前と全く同じか指定回になると終了する。MTMineRで、指定クラスター数のNum. of Clusterを2にし、指定最大計算回数Max. Num. of iterationsを10にする場合の結果を次に示す。各小説名の下にある数字の1と2はクラスラベルで、1は三島由紀夫、2は川端康成をそれぞれ表す。川端康成の『少年』と『岩に菊』は間違って三島由紀夫を表す「1」に判別されたことが見て取れる。
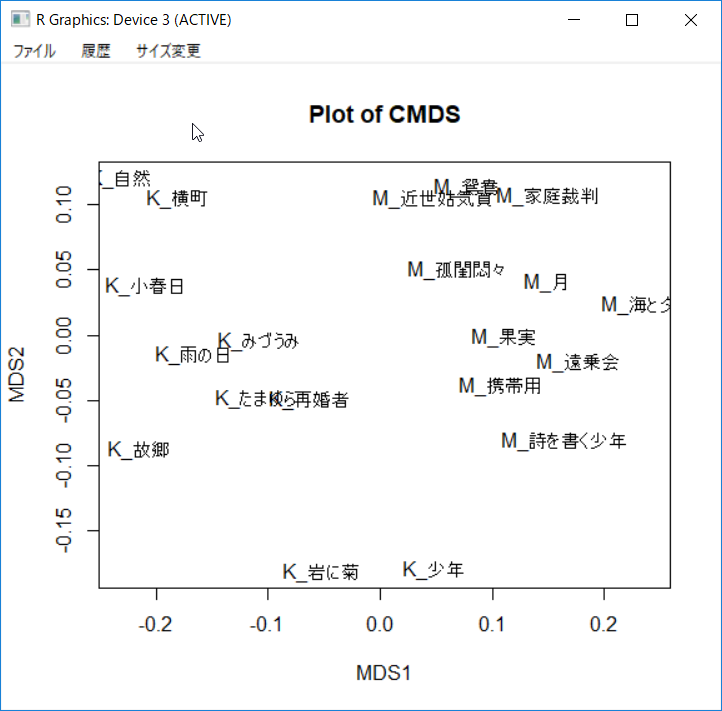
多次元尺度法 (Multidimensional Scaling)
多次元尺度法は個体間の親近性データを低次元(2或いは3次元)空間に配置する方法である。この方法は、計量的多次元尺度法と非計量多次元尺度法)に大別される。計量的多次元尺度法は個体間の距離データに基づいたもので、MTMineRではMethodタブのcmdscaleで対応している。非計量的多次元尺度法は個体間の類似度や相関係数行列に基づいたもので、MTMineRではMethodタブのisoMDS、sammonとmetaMDSで対応している。cmdscaleを用いた川端康成と三島由紀夫の分析結果では、両作家の作品は異なるグループを形成していることが見て取れる。
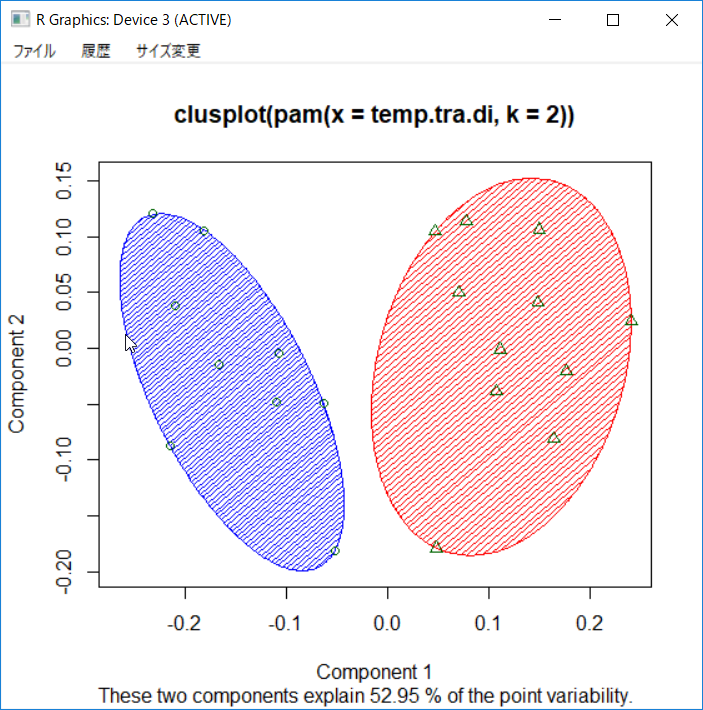
PAM法 (Partition Around Medoids)
PAM法はk-means法に似ているが、クラスターの中心ではなくmedoidで代表する点で異なる。Medoid以外の対象はそれと最も近いmedoidが代表するクラスターに分類される。その大まかなアルゴリズムは、(1)k個のmedoidを選択する(2)すべてのデータと中心との距離を求め、データを距離の最も近いmedoidが代表するクラスターに分類する。(3)全てのデータに対してmediodの再計算を行う(4)(2)と(3)を繰り返し、最適な分類に近づいていく。次のフラフに示したように、川端康成の作品(〇)と三島由紀夫の作品(△)は大まかに2群に分かれている。
LDA法 (Latent Dirichlet Allocation)
LDALDAはトピックモデルの一種latent dirichlet allocationの略語、階層的ベイズモデルのアプローチでpLSAを拡張したモデルである。MTMineRに実装されたLDAでは、文章の属するトピックの推定し、そのトピックごとのクラスタリングも行う。川端康成と三島由紀夫の作品におけるLDAの実行結果を次の図に示す。作品は2群に分かれていることが見て取れる。