タグ付きテキスト
タグ付きのデータは大きく3種類:
- 自由に作成したタグ付きテキスト
- 形態素解析器により形態素の属性が付けられたテキスト
- Cabochaにより文節に切り分けたテキストに分けられる
MeCab、ChaSen、JUMANがインストールされ、パスが通されている環境では、平テキストを読み込みMTMineRでメニュー操作により形態素解析を行い、タグを付け集計を行うことが可能である。
下図から分かるように、これらのタグ付きテキストについても9つのタブが用意されている。
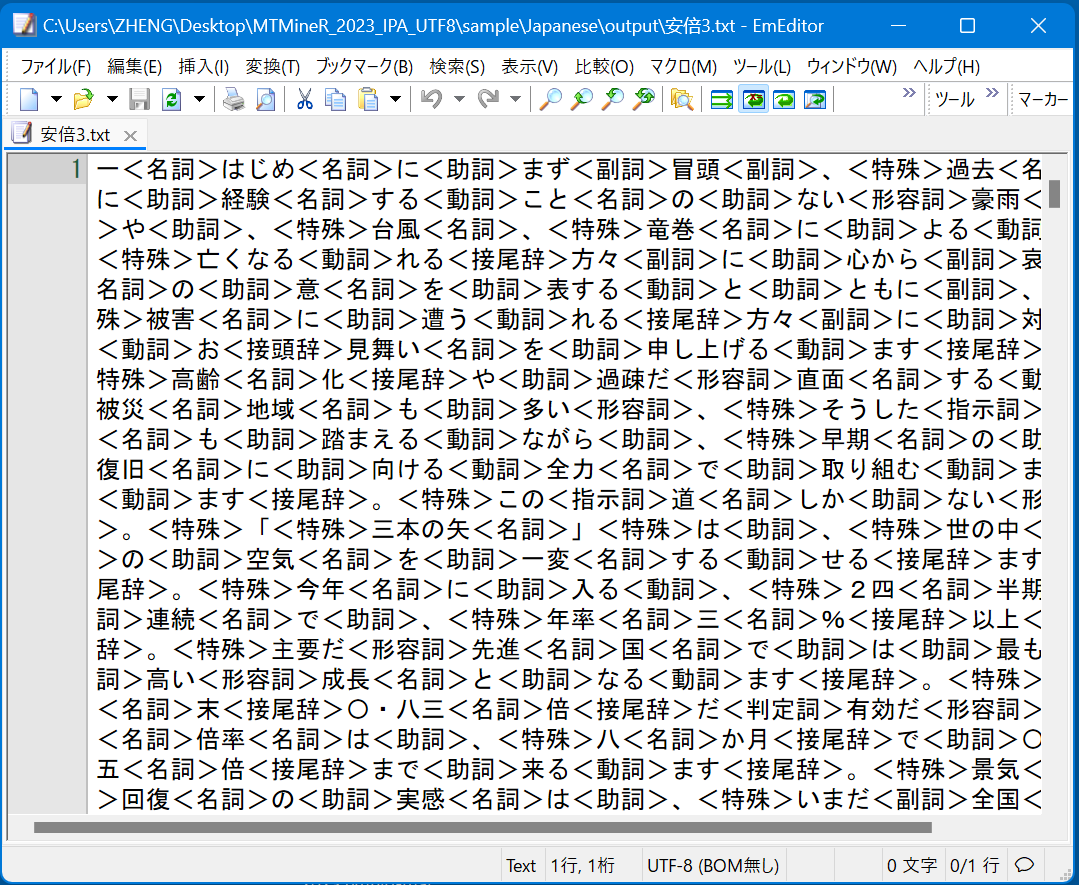
1.File List(データの読み込み)
ボタン「Add New Files」を用いてファイルの読み込みを行う。ボタン「Add New Files」を押すとファイルが置かれている場所を指定する画面が開かれる。ドライブ、フォルダ、サブフォルダ順に選択し続け、読み取りたいテキストを選択し、画面上の「開く」ボタンを押すと選択されたテキストがMTMineRのタブ「File List」の左の窓にリストアップされる。
MeCab、ChaSen、JUMANによって形態素解析を行ったテキストを読み込み処理するときには、画面の上部の三種類の形態素解析器の名前にラジオボタンを押す。
形態素解析結果のファイルを読み込んで用いるときには、tagged<>を選ぶ。
「Plain Style」をチエックすると、形態素の原形は集計される。
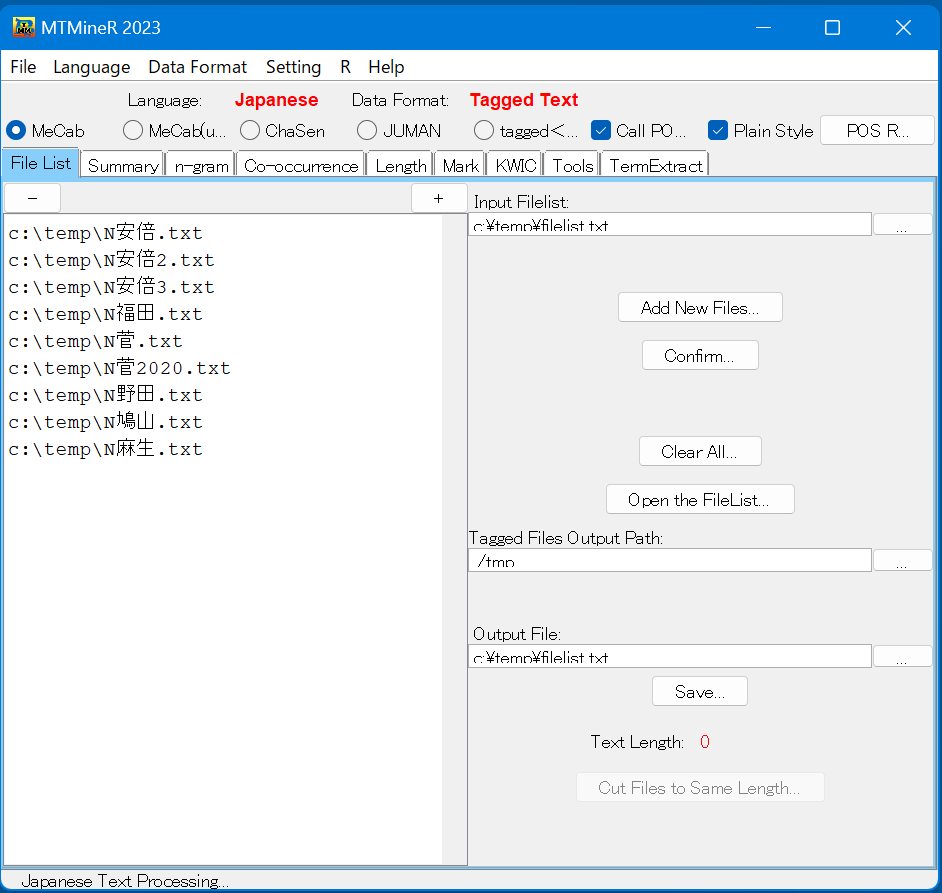
ChaSenとMeCabの結果の場合は、「POS Renaming」ボタンを押し、品詞の命名を行う。
「POS Renaming」を押すと下図のような品詞を命名する窓が開かれる。黒字は形態素解析器の結果であり、青色縦棒の右の赤文字は自由に書き換えられる形態素の属性である。
属性の命名が終わったら確認ボタン「Confirm」を押す。
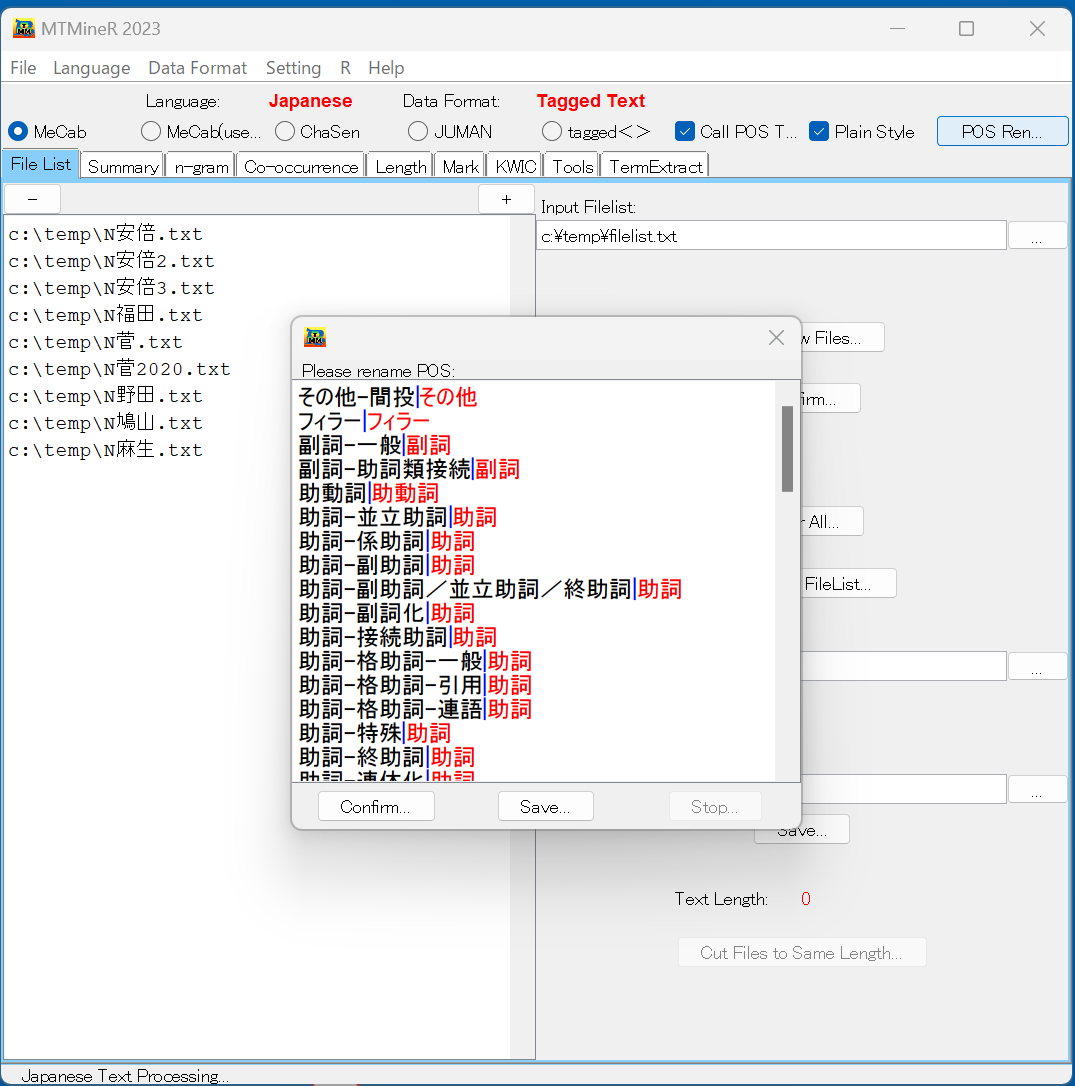
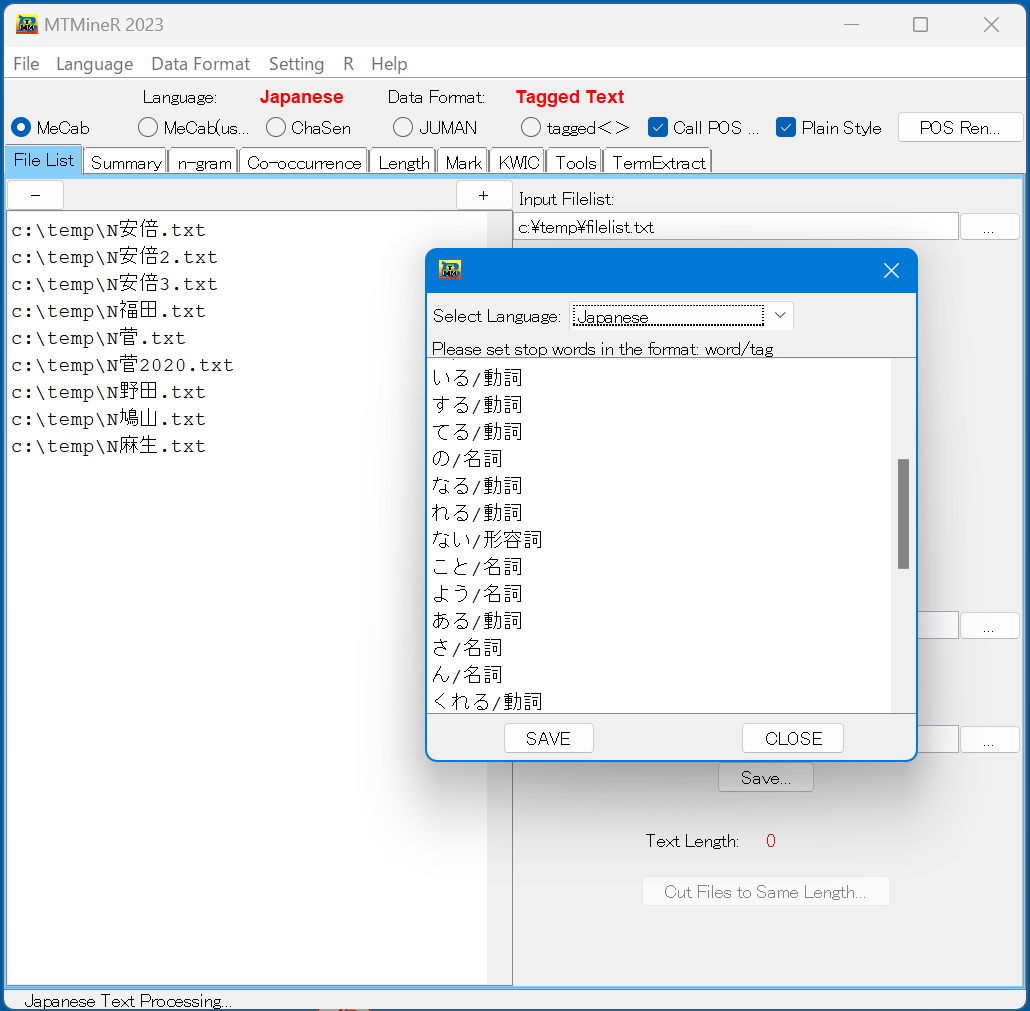
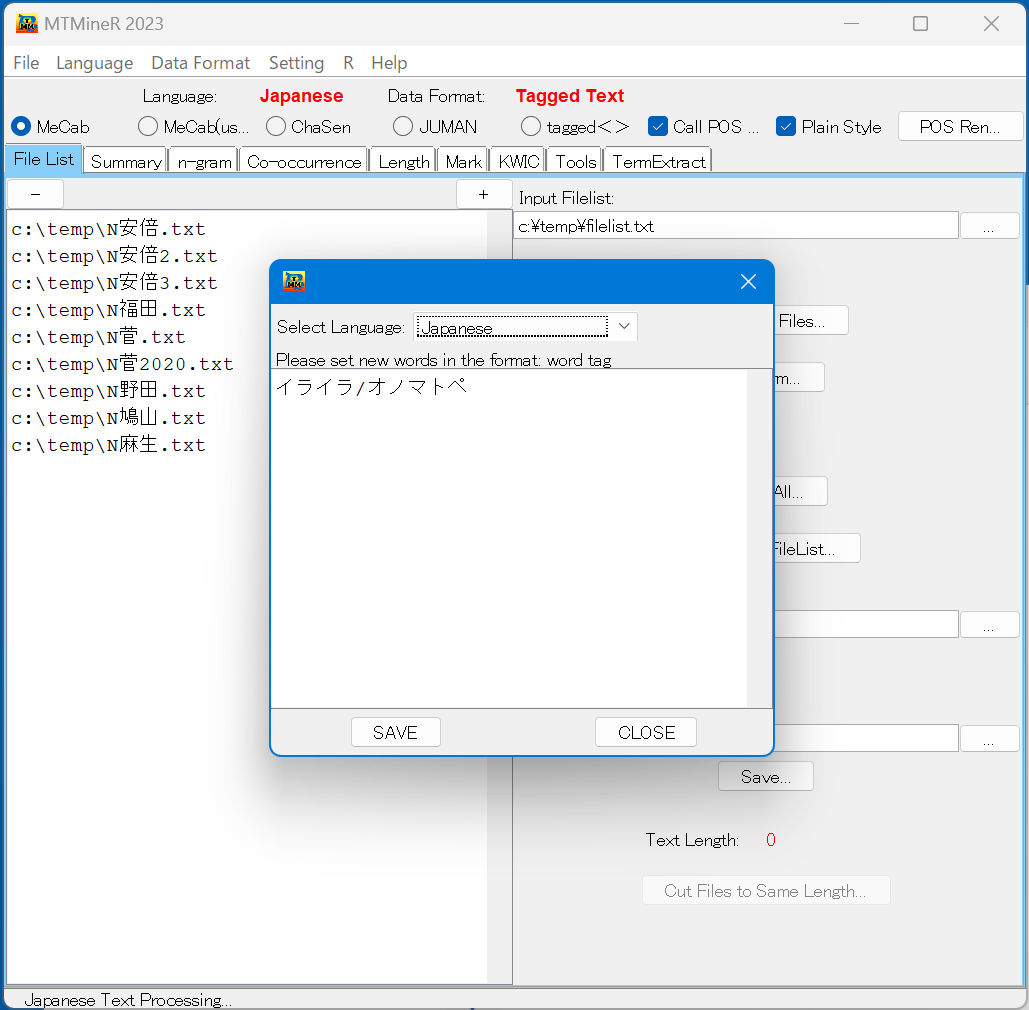
メニューバーの「Setting」を押すと、Stop wordsの設定とMeCab辞書追加ができる。
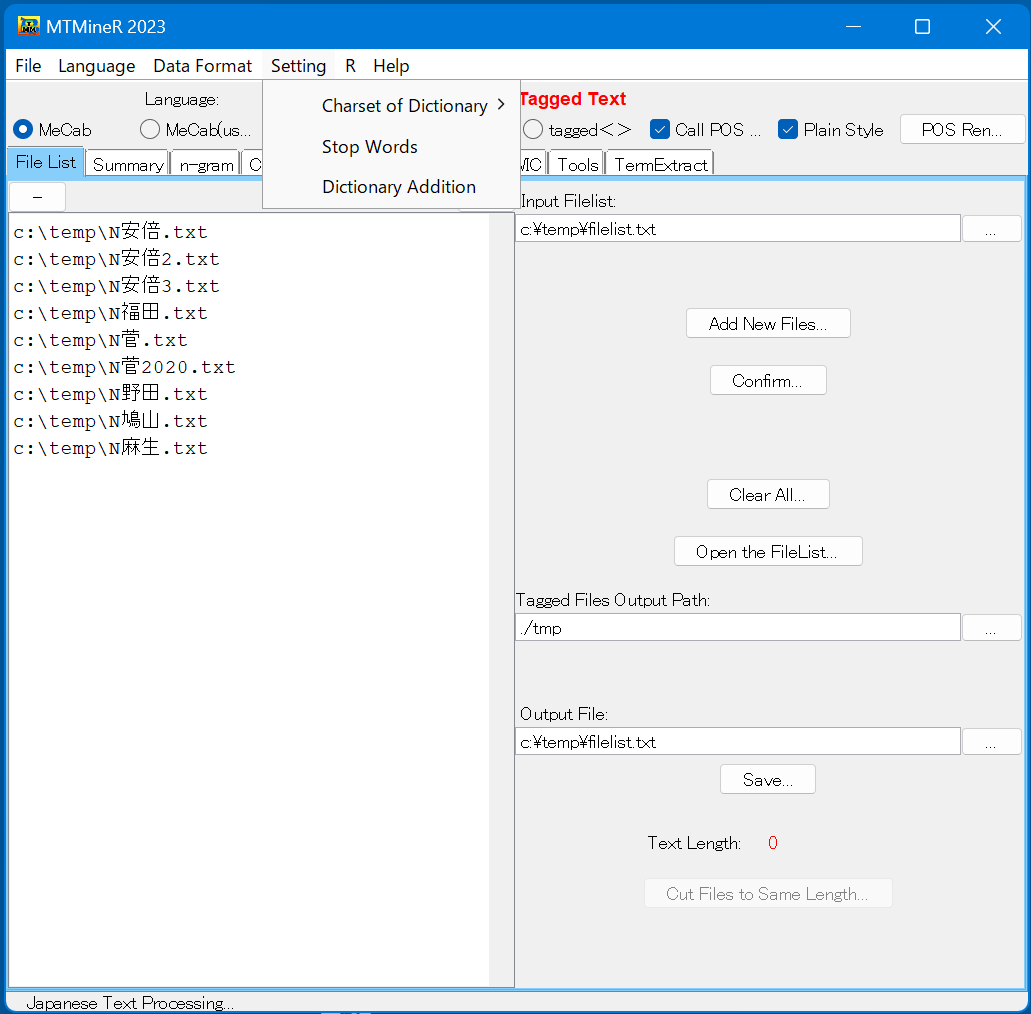
- Stop wordsの設定 一つのStop wordを一行にして、「word/tag」の形式で設定する。例えば、「いる/動詞」をStop wordsに追加すれば、「いる/動詞」は集計されない。
- MeCab辞書追加 一つのStop wordを一行にして、「word/tag」の形式で設定する。
複数がある場合、中にコピペできる。
終わったら、「SAVE」を押し、窓口を閉じる。
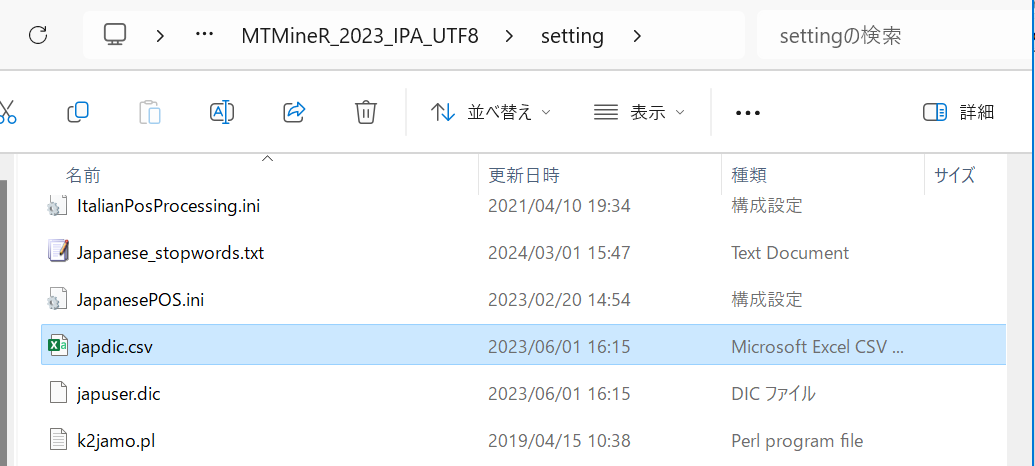
あるいは、フォルダ「Setting」の中の「japdic.csv」の中に書き込むことも辞書追加ができる。
辞書追加した後、「MeCab(userdic)」を選び、形態素解析を行う。
2.Summary(データの要約)
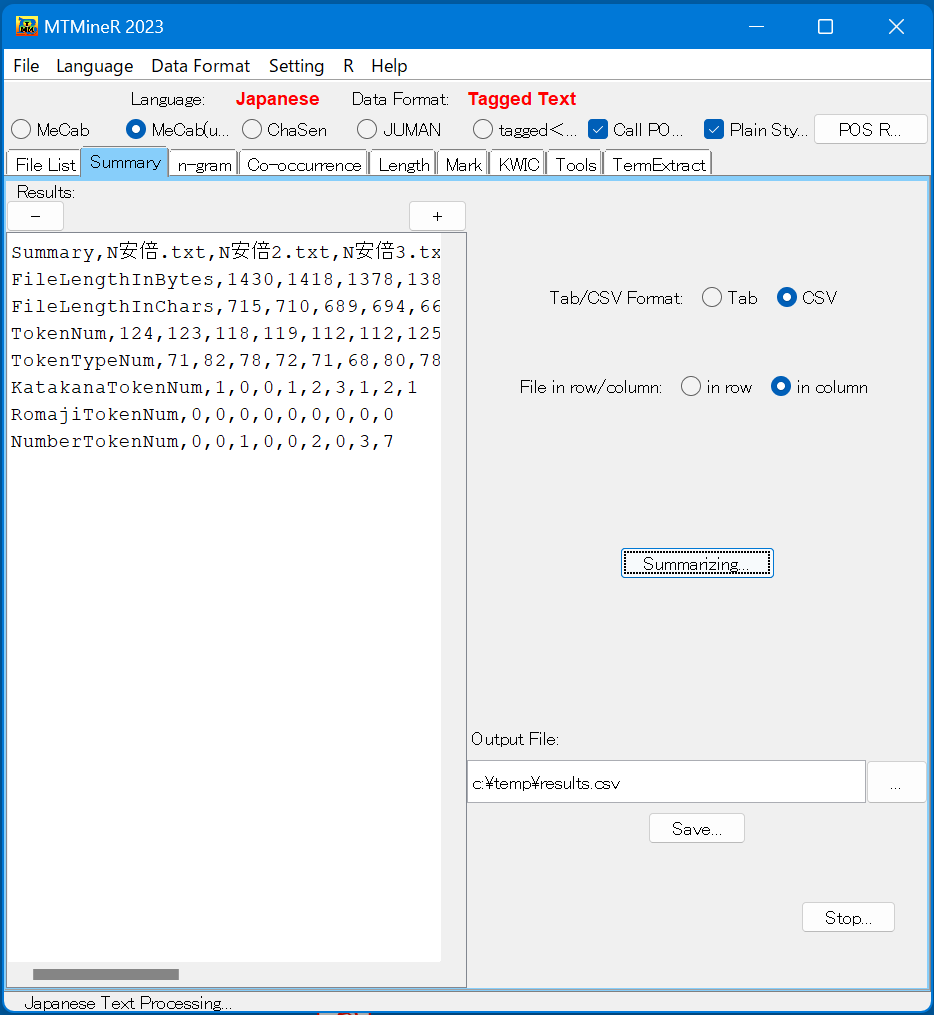
タブ「Summary」では、 半角と全角によるテキストのサイズ(File Length In Byte,Files Length In Char)、述べ語数(Token Num)、 異なり語数(Token Type Num)、片仮名語の数(Katakana Token Num)、ローマ字語の数(Romaji Token Num)、数値の数(Number Token Num)を集計する。
ボタン「Summarizing」を押すと集計結果が左側の窓に返される。
データの形式は画面の右側のラジオボタンで指定できる。「Tab format」はデータをタブで区切り、「CSV format」はデータをコンマで区切る。「File in row」はデータを行で、「File in column」はデータを列で表示する。集計したデータを保存する時、保存の場所とファイル名前を指定し、ボタン「Save」を押すと保存される。
Go To Top
3.n-gram
タブ「n-gram」ではタグ(Tag)、形態素(Word)、タグ付いた形態素(Word Tag)のn-gramを集計する。
まず、処理の種類(Processing Type)のTag、Word、WordTagから一つを指定する。そして、「Ngram Type」下の窓でnを選択する。 中にはUnigram(n=1), Bigram(n=2), Trigram(n=3), Fourgram(n=4), Fivegram(n=5), Sixgram(n=6)という6つの選択肢がある。
次に「Cutoff」を用いて集計サイズをコントロールする。デフォルトは100になっている。Cutoff値が100の場合は、100文字以上の文はすべて一つの項目にまとめて集計する。
データの形式は画面の右側のラジオボタンで指定できる。「Tab format」はデータをタブで区切り、「CSV format」はデータをコンマで区切る。
「File in row」はデータを行で、「File in column」はデータを列で表示する。
「All Tag Processing」を押すと集計結果が左側のResults窓に返される。下図はタグを集計した画面である。
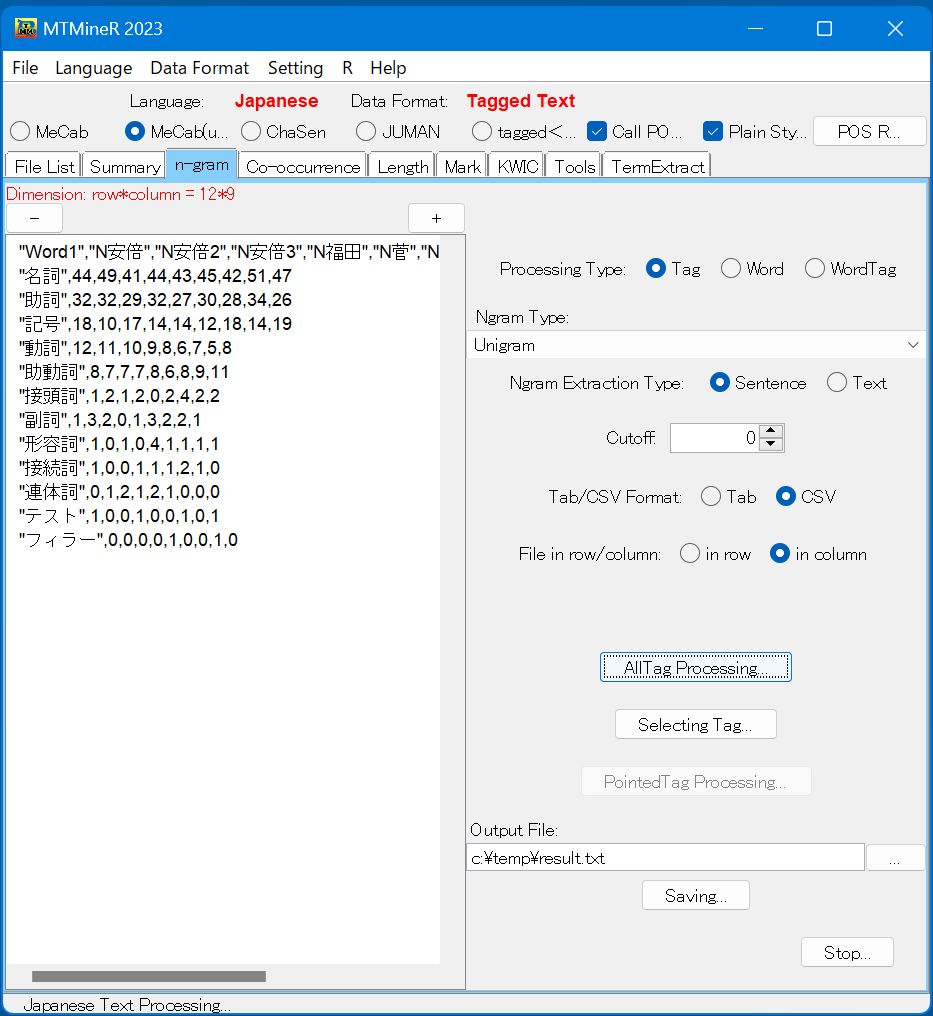
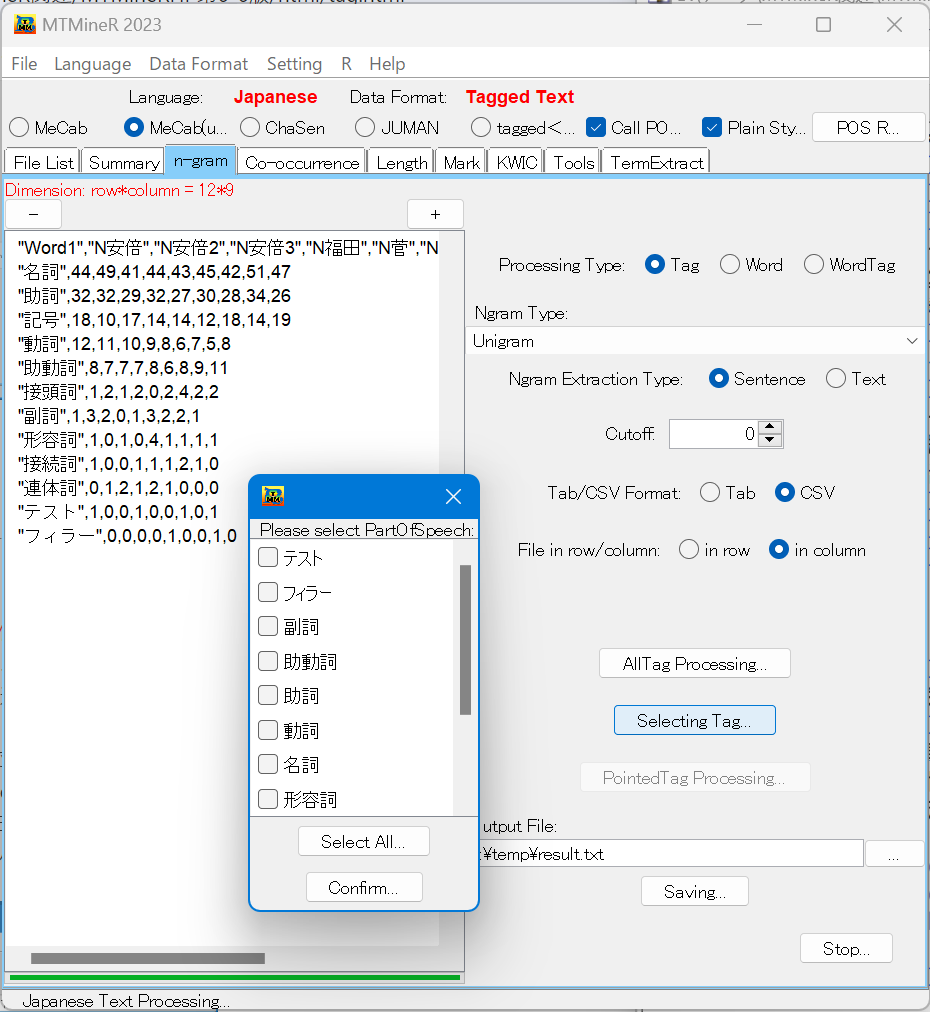
タグの種類を指定し、集計を行うためにはタグを指定するボタン「Selecting Tag」を押し、タグを指定することが必要である。ボタン「Selecting Tag」を押すと、次のようなタグ選択画面が表れる。
タグの前にチェックを入れ、確認ボタン「Confirm」を押し、画面上の「Pointed Tag Processing」を押すと集計結果が左側の窓に返される。
Go To Top
4.Co-occurrence(共起)
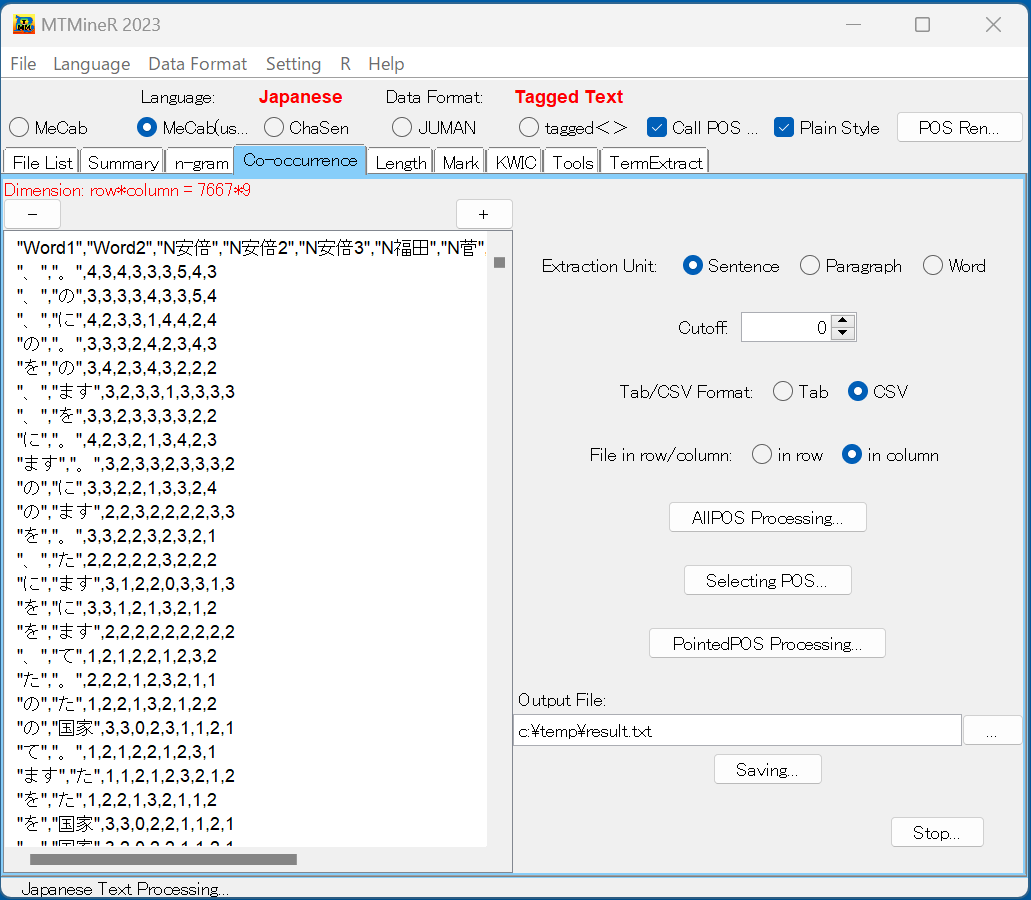
タブ「Co-occurrence」では、形態素の共起データを集計する。
集計するのはタグに基づいた形態素の共起である。n-gramの場合と同じく、すべての形態素の共起と指定したタグのみの形態素の共起を集計することができる。
抽出ユニットは、文(Sentence)、段落(Paragraph)、Word(単語)から選べる。文/段落にする場合、同じ文/段落に同時に出現すれば、共起として数える。 単語にする場合、連続の形態素を共起として数える。
「AllPOS Processing」を押すと、全ての形態素の共起についての集計結果が左側のResults窓に返される。
指定したタグのみの形態素の共起を集計したい時に、タグを指定するボタン「Selecting POS」を押し、タグを指定することが必要である。ボタン「Selecting POS」を押してタグの選択ができる。
タグの前にチェックを入れ、確認ボタン「Confirm」を押し、画面上の「PointedPOS Processing」を押すと集計結果が左側の窓に返される。
Go To Top
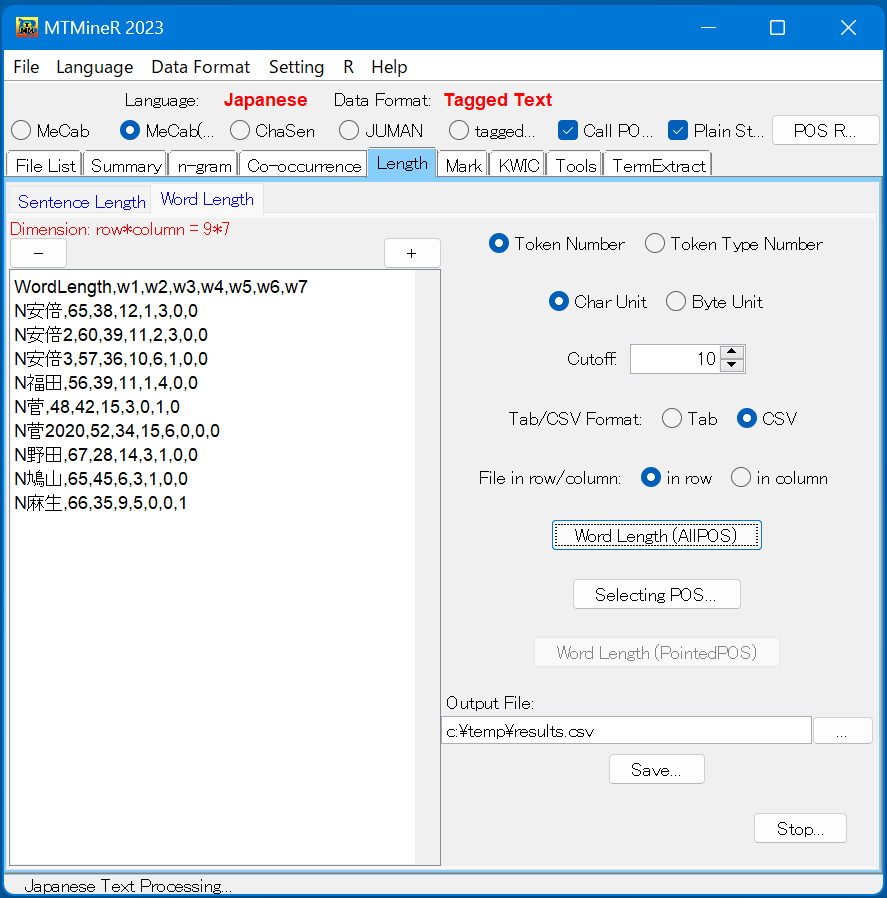
5.Length(文の長さ、形態素の長さ)
タブ「Length」には、 「Sentence Length」、 「Word Length」という二つのサブタブがあり、それにより、文の長さ、文字単位で形態素の長さを集計することができる。
- 「Sentence Length」 文の長さを集計するとき、延べ語数「Token Number」で数えることができ、異なり語数「Token Type Number」で数えることも可能である。
- 「Word Length」 集計するのは、延べ語数「Token Number」、異なり語数「Token Type Number」にすることが可能である。
画面上の「Category Index」により、いくつの形態素を1つの項目にまとめて集計することを指定できる。 k個の形態素をまとめて一つの項目にする時には、Category Indexの窓に数値kを指定する。
Cutoff値が100の場合は、100文字以上の文はすべて一つの項目にまとめて集計する。
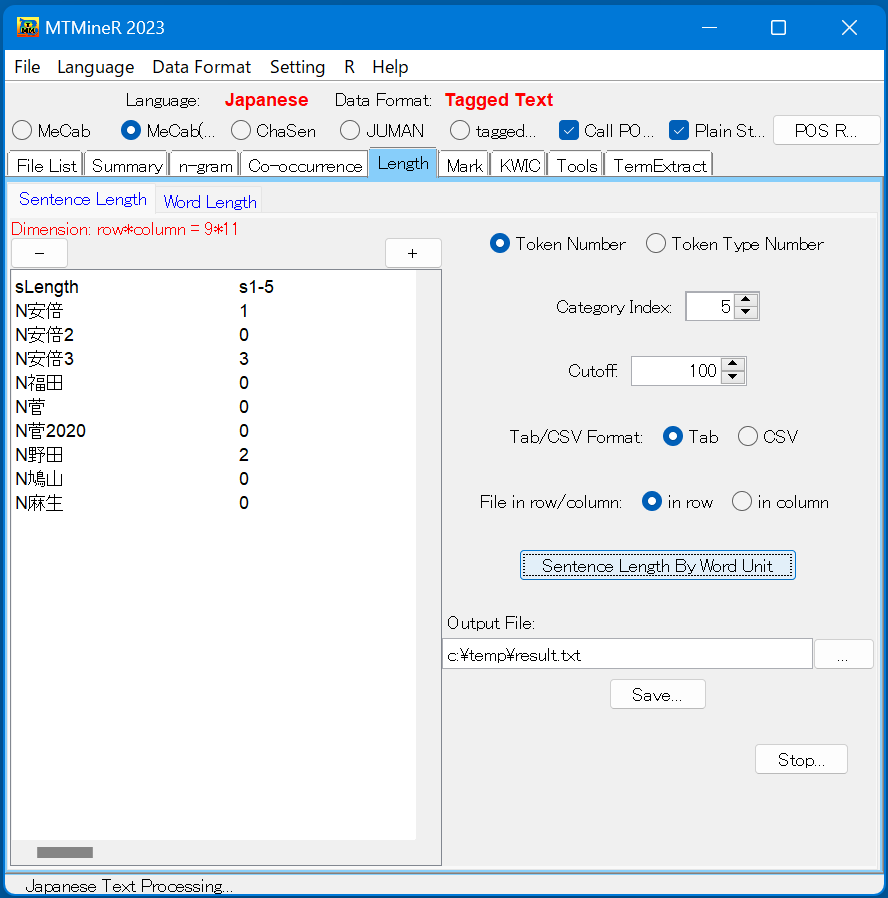
形態素の長さの計測は、文字を単位とする時は「Char Unit」を選択し、バイトを単位とする時は「Byte Unit」を選択する。
そして、ボタン「Word Length(AllPOS)」を押すと、全部の形態素の長さについての集計結果が左側の窓に返される。特定したタグの形態素の長さを集計する時、タグを指定するボタン「Selecting POS」を押し、タグ選択画面が開かれる。対象タグの前にチェックを入れ、確認ボタン「Confirm」を押し、画面上の「PointedPOS Processing」を押すと集計結果が左側の窓に返される。
w1は長さは1文字の単語、w2は長さは2文字の単語...集計された数字は、延べ語数、または異なり語数でなる。
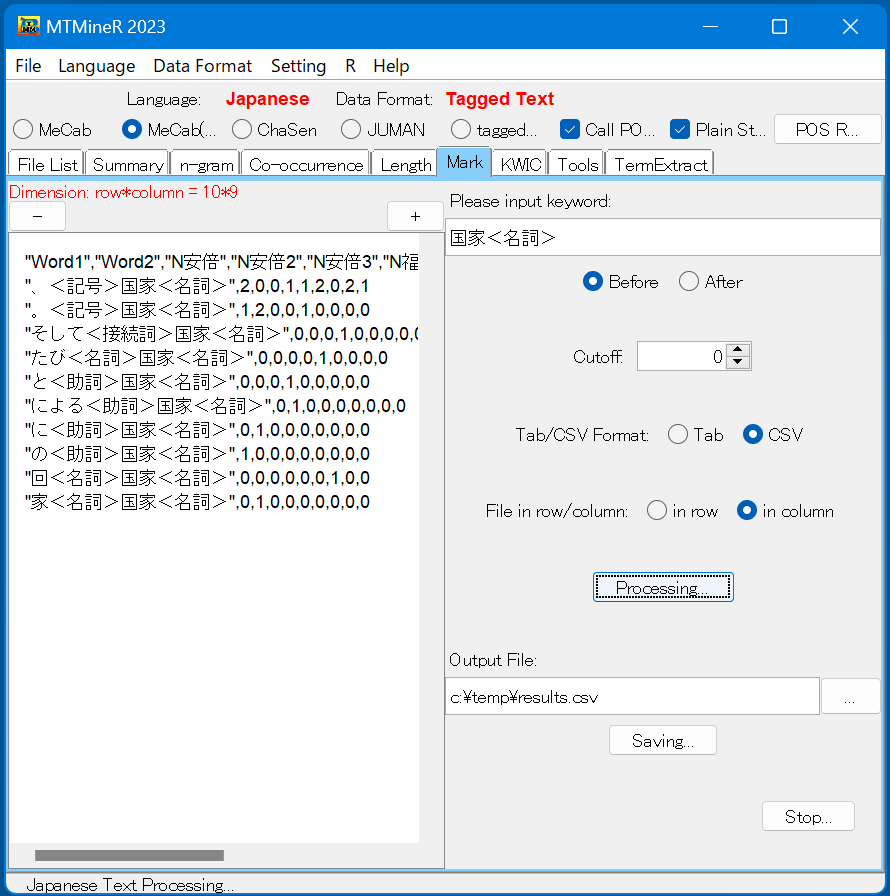
6.Mark(指定した形態素の前後の形態素)
タグ「Mark」では、ある形態素の前後のデータを集計する。
たとえば、名詞「国家」がどの形態素の前に位置するかを集計する際には、キーワードを記述する「Please input Keyword」の窓に「国家<名詞>」のカギ括弧の中のものを入力する。画面上のボタン「Processing」を押すと、集計結果が左側の窓に返される。
尚、「Cutoff」を用いて集計サイズをコントロールすることができる。Cutoff値が100の場合は、100文字以上の文はすべて一つの項目にまとめて集計する。
Go To Top
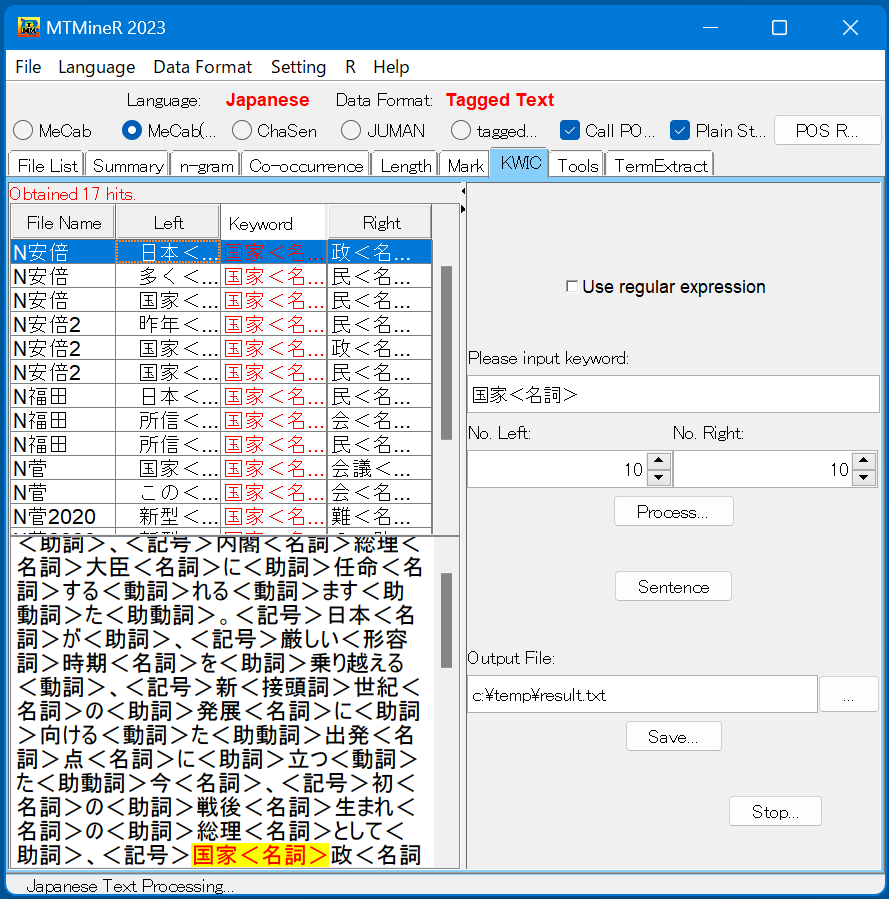
7. KWIC(タグ付きのKWIC検索)
タグ「KWIC」では、タグ付きのテキストから指定したキーワードの前後を切り取り返す。
たとえば、名詞「国家」を含む全ての文を抽出するとき、キーワードを記述する「Please input Keyword」の窓に「国家<名詞>」を入力し、ボタン「Sentence」を押すと、結果が左側に返される。
返された結果は自由にソートすることができる。切り取った部分の前後を基準としたソートは、左側の画面上の「Left」或は「Right」の部分をクリックすると降順、昇順に入れ替わる。
返された結果の一行をクリックするとそれが含まれているテキストが左下側の空白欄に返される。
画面の右側の「Use regular expression」の前にチェックを入れば、キーワードを正規表現(regular expression)で指定できる。
Go To Top
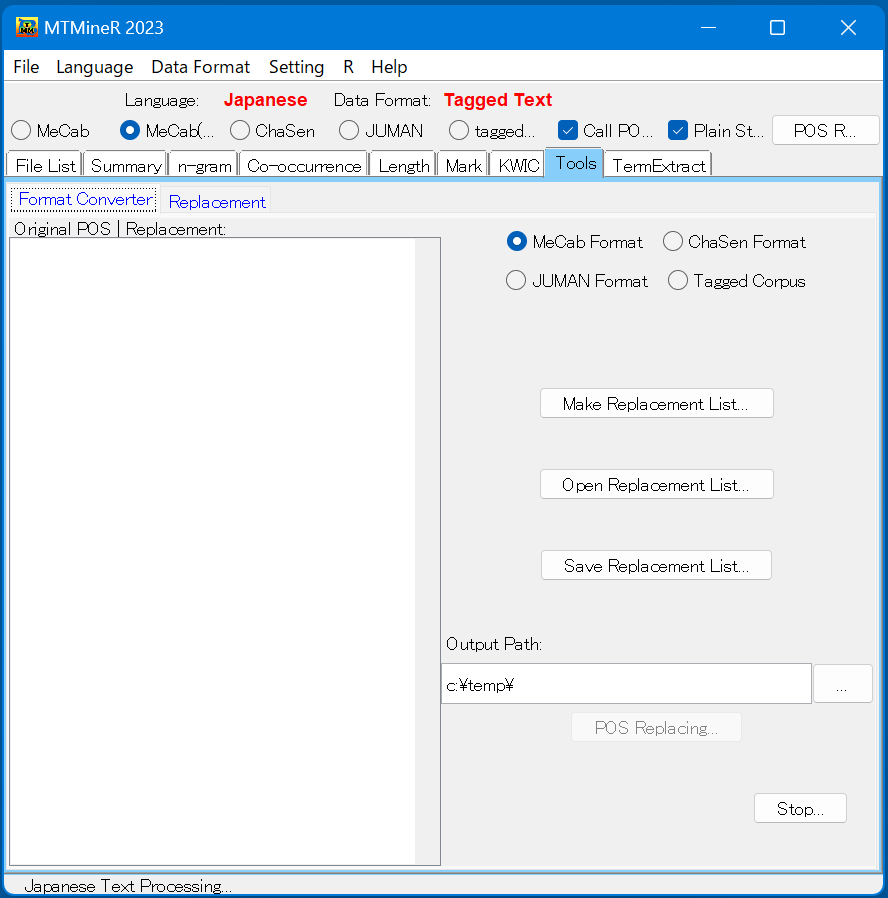
8.Tools
タグ「Tools」には、「Format Converter」と「Replacement」という二つのサブタブがある。
サブタブ「Format Converter」ではJUMAN、ChaSen、MeCabで形態素解析を行った結果をカギ括弧<>でタグ付けるなどの処理を行うことができる。
「Replacement」では置き換え処理ができる。
Go To Top
9.TermExtract
タグ「TermExtract」は、TermExtractを借用し、専門用語(キーワード)を抽出する機能である。
TermExtractはPerlで動作しているため、Perl(5.30.3.1)をインストールする必要である。
Go To Top