教師あり分析方法
タブSupervisedには教師ありの方法を実装している。- ●CART
- ●C50
- ●k-Nearest Neighbour
- ●RandomForest
- ●SVM(support vector machine)
- ●LDA(supervised LDA)
- ●HDDA(High-Dimensional Discriminant Analysis)
MTMineRの中のすべての関数表示は各自のRパッケージと同じである。関数の意味を各パッケージのサイトに確認してください。
これらの方法を用いるためには、まず教師となる外的基準を指定しなければならない。外的基準の指定はタブGroupingで行う。
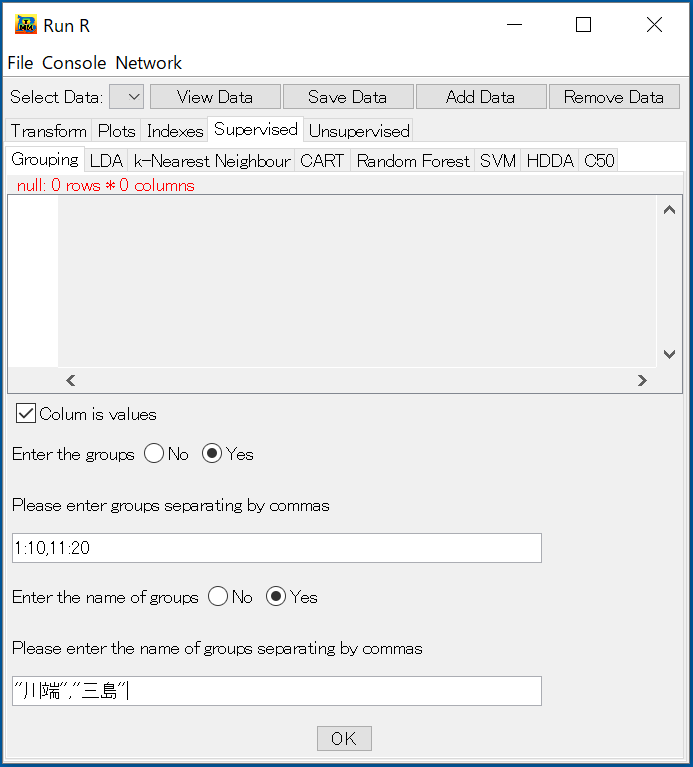
Grouping
①各グループの範囲を指定する。②各グループにラベルを付ける。
③OKを押すと、ラベル付きデータセットを作成する。作成したデータセットをSelect Dataの中に指定する。
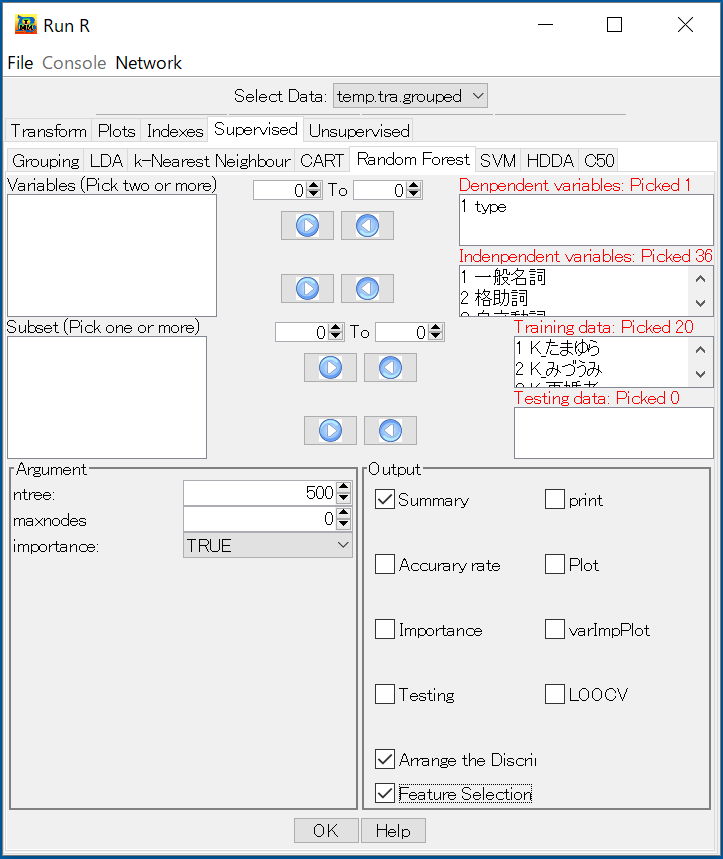
Random Forest
最初に目的変数①、説明変数②、学習データ③とテストデータ④を入れる。●Arrange the Discrimination Maker:
MeanDecreaseAccuracyで決めった変数重要度により、降順で変数を並べ替える。第一列は最も重要な変数である。結果をarrangeに入れておく。 "arrange"を左上のR Consoleに入力すると変数を並べ替えた結果を示す。
●Feature Selection:
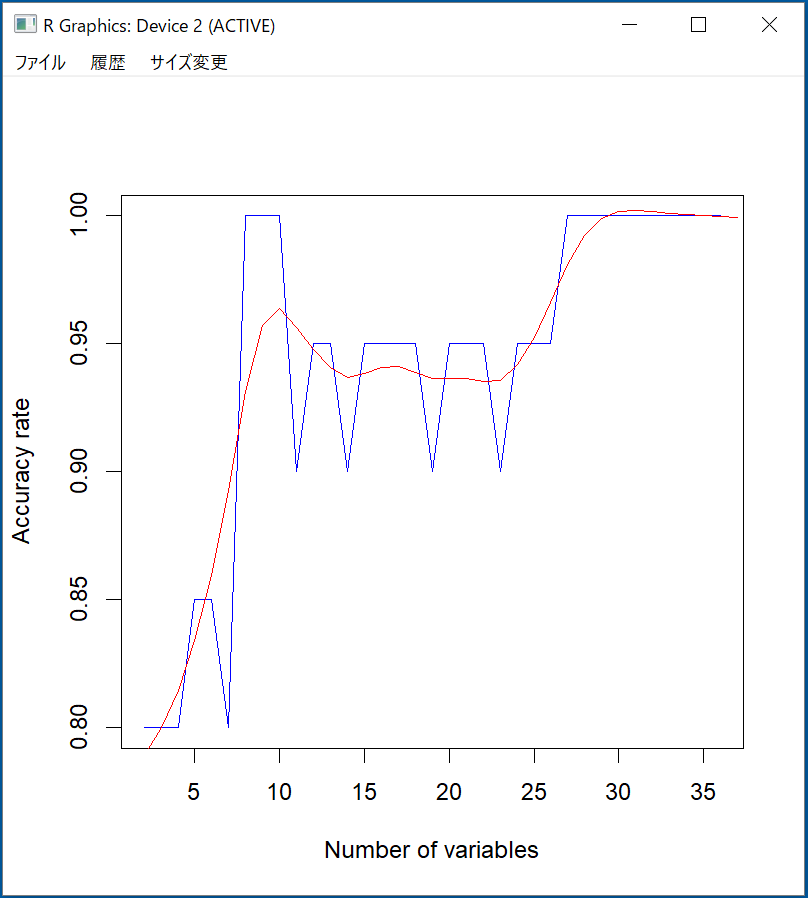
並べ替えたベクトルを用いて、最初は一つの変数、一つずつを増やしてそれぞれの正判別率を計算し、結果をSmatrixに入れておく。
図に示しているのように、前26位の変数を用いる場合は正判別率が最も高い。
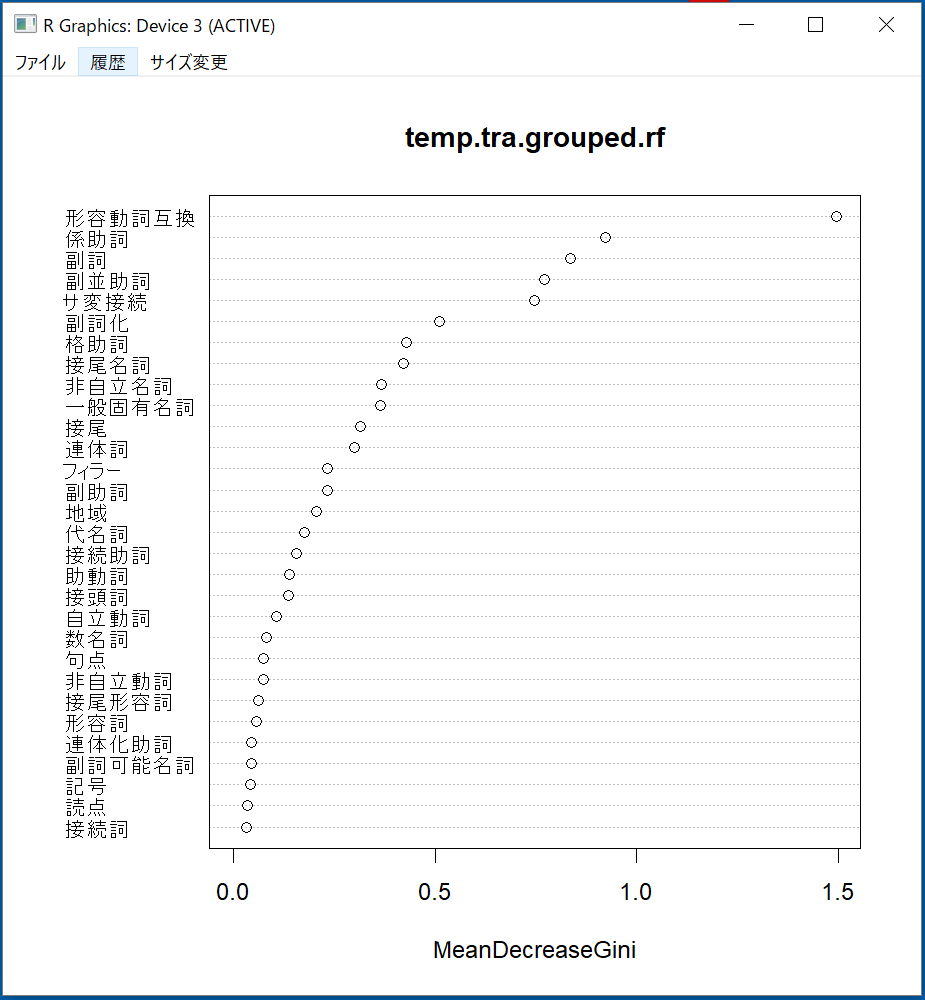
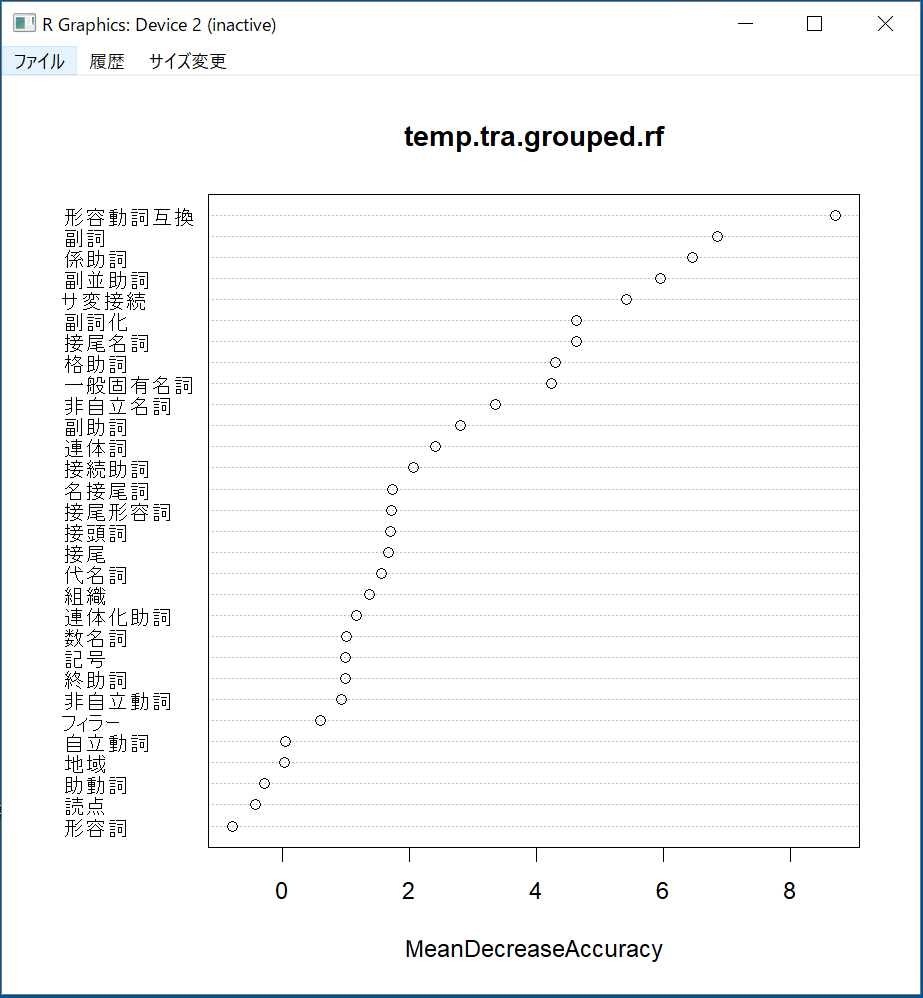
●VarImpPlot:
「MeanDecreaseAccuracy」と「MeanDecreaseGini」二つのアルゴリズムで変数重要度を出す。