平テキスト
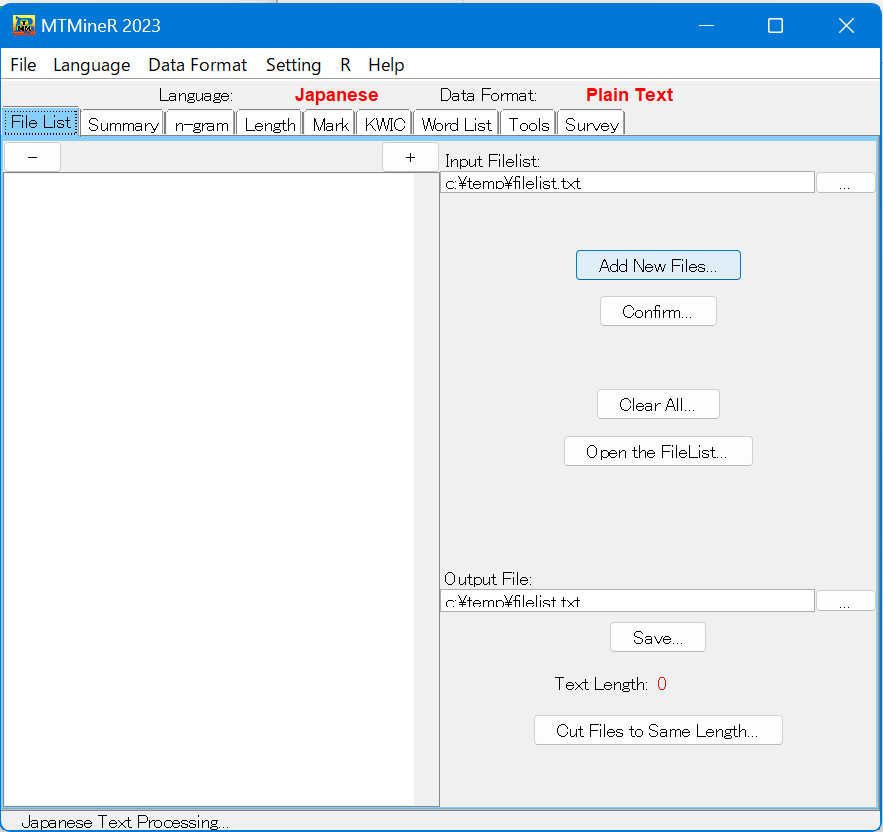
平テキストの画面には、メニューの下に8つのタブが用意されている。1.File List(データの読み込み)
ボタン「Add New Files」を用いてファイルの読み込みを行う。
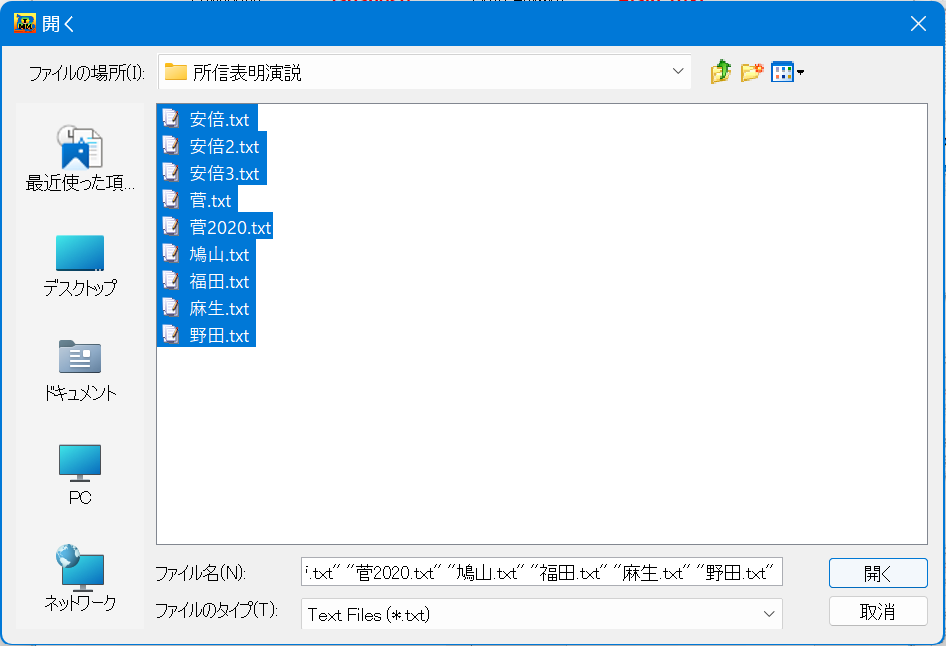
ボタン「Add New Files」を押すとファイルが置かれている場所を指定する画面が開かれる。下図のように読み取りたいテキストを選択し、画面上の「開く」ボタンを押すと選択されたテキストがMTMineRのタブ「File List」の左の窓にリストアップされる。
確認ボタン「Confirm」を押す。
- ファイルの追加・削除 ほかのフォルダ中のファイルを追加したいときには、上記の操作を繰り返す。
- ファイルリストの保存 「Save」ボタンを用いて、リストアップしたリストを保存しておくことができる。これにより、後日にリストアップしたファイルを利用する時、再びリストアップしなくて済む。
- 同じ長さのテキストの作成 ボタン「Cut Files To The Same Length」は、ファイルを同じの長さに前から切り取るためのボタンである。
個別ファイルを削除したい場合,左の窓のファイルリストからファイルを選択し,「backspace」/ 「del」で削除できる。
ファイルリスト画面のクリアはボタン「Clear All」を用いる。
「Save」を押すと、読み込んだファイルの長さの範囲は「Text Length」に反映される。
ファイルリストの保存は、まず「output File」の下の窓に保存する場所とファイル名前を指定し、次に「Save」ボタンを押す。ファイルの場所の指定は窓の右側のボダンを用いることが可能である。
保存したファイルリストを読み込んで用いる際には、ボタン「Open the file list」を用いて保存しておいたファイルリストを指定する。
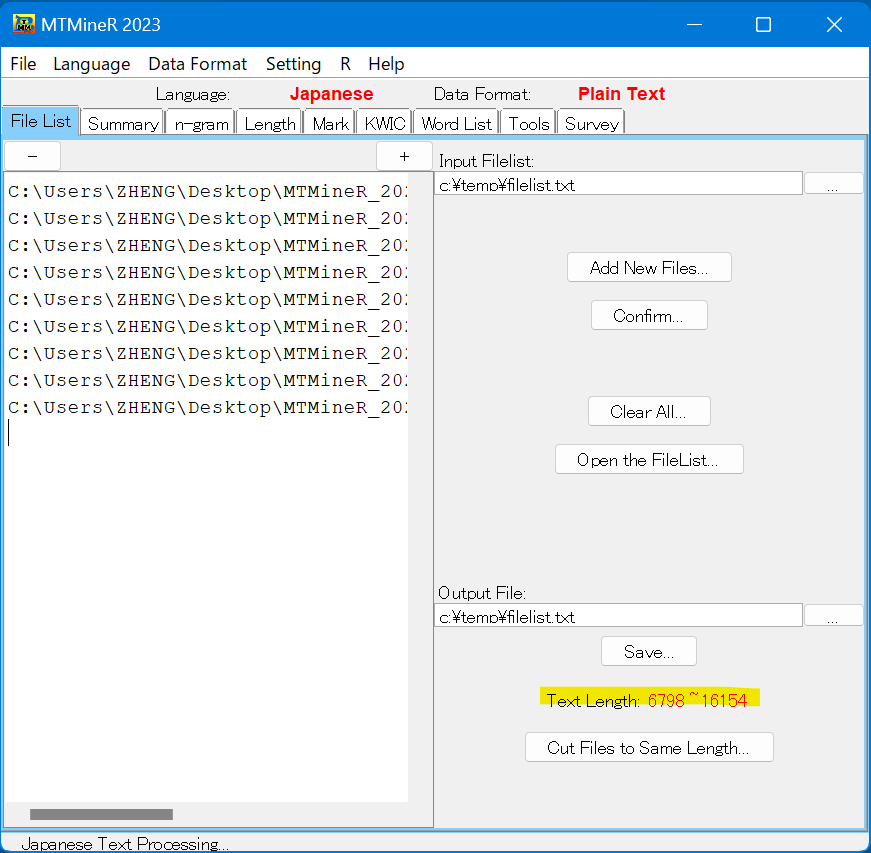
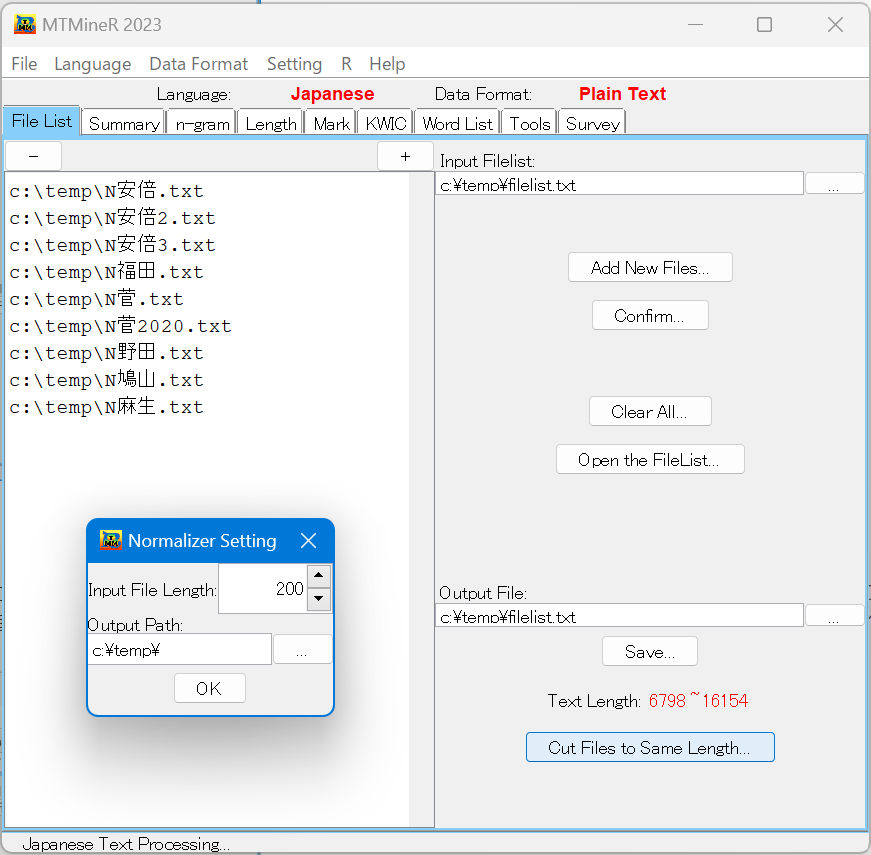
これを押すと、ファイルの長さ及び出力場所を指定する画面が開かれる。デフォルトではファイルの長さが200(全角文字数)になっている。
テキストの長さと出力場所を指定し、画面上の「OK」ボタンを押すと同じ長さに切り取ったテキストが保存され、当時にそのファイルがMTMineRにリストアップされる。
Go To Top
2.Summary(データの要約)
タブSummaryは、読み込んだテキストについて、
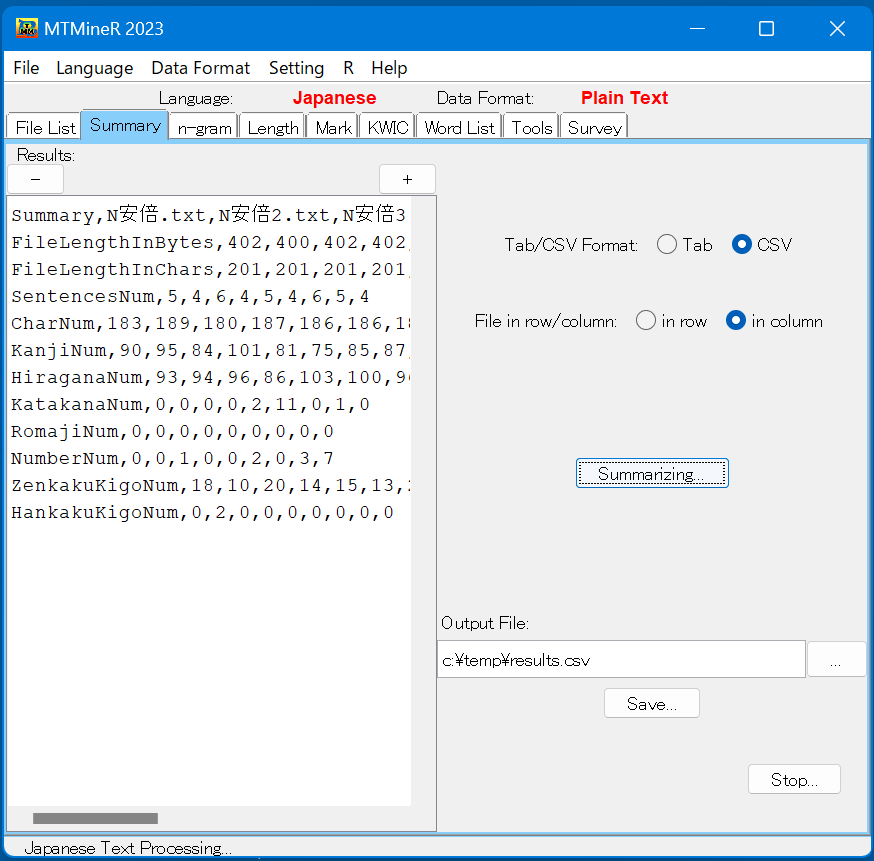
バイト数(FileLengthInBytes)、文字・記号数(FileLengthInChars)、文の数(SentencesNum)、文字の数(CharNum)、漢字の数(KanjiNum)、平仮名の数(HiraganaNum)、 片仮名の数(KatakanaNum)、ローマ字の数(RomajiNum)、数字の数(NumberNum)、全角記号の数(ZenkakuKigoNum)、半角記号の数(HankakuKigoNum)を集計する。
ボタン「Summarizing」を押すと集計結果が左側の窓に返される。
データの形式は画面の右側のラジオボタンで指定できる。
「Tab format」はデータをタブで区切り、「CSV format」はデータをコンマで区切る。
「File in row」は個体(テキスト)を行に、「File in column」は個体を列に表示する。
集計したデータを保存する時、保存の場所とファイル名前を指定し、ボタン「Save」を押すと保存される。あるいは、データをコピーし、直接エクセルに貼り付ける。
Go To Top
3.n-gram
タブn-gramでは、文字単位のn-gramのデータを集計する。
画面の右側の「Ngram Type」下の窓でnを指定する。中にはUnigram(n=1), Bigram(n=2), Trigram(n=3), Fourgram(n=4), Fivegram(n=5), Sixgram(n=6)という6つの選択肢がある。
集計結果のサイズはcutoff値(閾値)を用いてコントロールできる。例えば、Cutoff値を100すると全対象テキストにおいて合計の頻度が100未満の項目はすべて、1つの項目“OTHERS”にまとめる。集計したデータは総度数が大きいものから降順にソートされている。
ボタン「Processing」を押すと、集計結果が左側の窓に返される。
結果の保存は、Output Fileの窓にフォルダを指定し、ファイルの名を付け、ボタン「Saving…」を押す。あるいは、データをコピーし、直接エクセルに貼り付ける。
Go To Top
4.Length(長さの分布)
タブLengthでは、文の長さ(Sentence Length)と段落の長さ(Paragraph Length)、リズムの長さ(Rhythm Length)を集計する。
文については句点、感嘆符、疑問符を文の終わりと判断する。
これらの記号を用いず、改行を文の終わりとしている場合は画面上の「Use line break to split sentence」にチックをいればよい。
リズムはコロン、セミコロン、読点、句点、感嘆符、疑問符をリズムの区切りとする。
平テキストの場合は、長さを集計する際、一般的には文字単位として「Length in Character」を集計する。
Mecabがインストールされている環境では、漢字を読み方に置き換え、読み方による長さ「Length in Reading」を集計することも可能である。
形態素解析済みの場合、一般的には延べ語数「Token Number」を単位として集計するが、異なり語数「Token Type Number」で集計ことも可能である。
文字を単位とする時は「Char Unit」を選択し、バイトを単位とする時は「Byte Unit」を選択する。
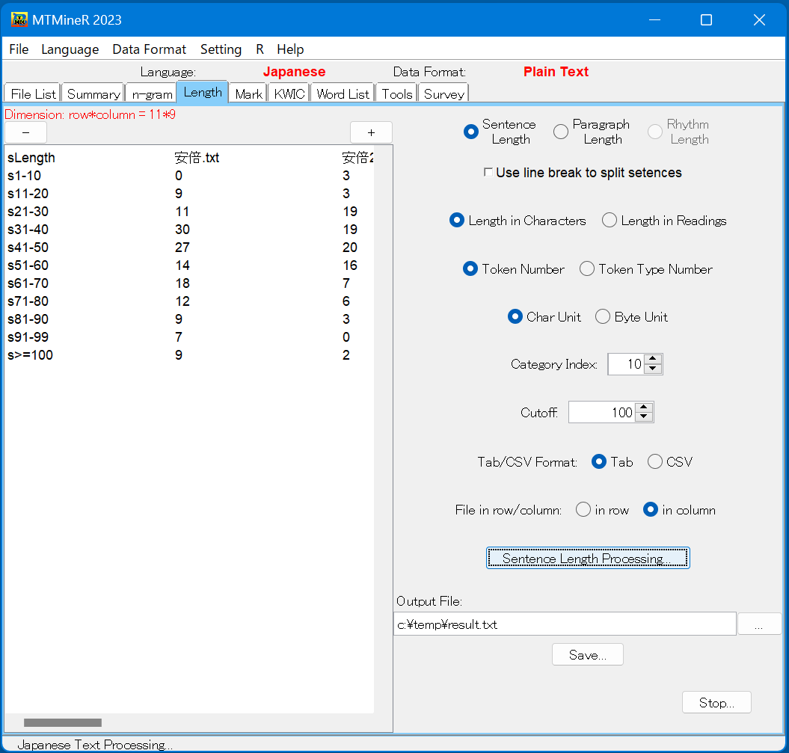
長さの分布のデータを集計する際、1文字ごとに一つの変数(項目)にするとデータのサイズ大きくなるので、いくつの文字を1つの項目にまとめて集計すると便利である。これは画面上の「Category Index」で自由に指定できる。
例えば、文字を単位とした場合、Category Indexが5であると1文字から5文字を1項目、6文字から10文字を1項目のように集計する。
画面上の「Cutoff」(閾値)を用いて集計サイズをコントロールすることができる。デフォルトは100になっている。Cutoff値が100の場合は、100文字以下の文はすべて一つの項目にまとめて集計する。
Go To Top
5.Mark(指定文字・記号の前後)
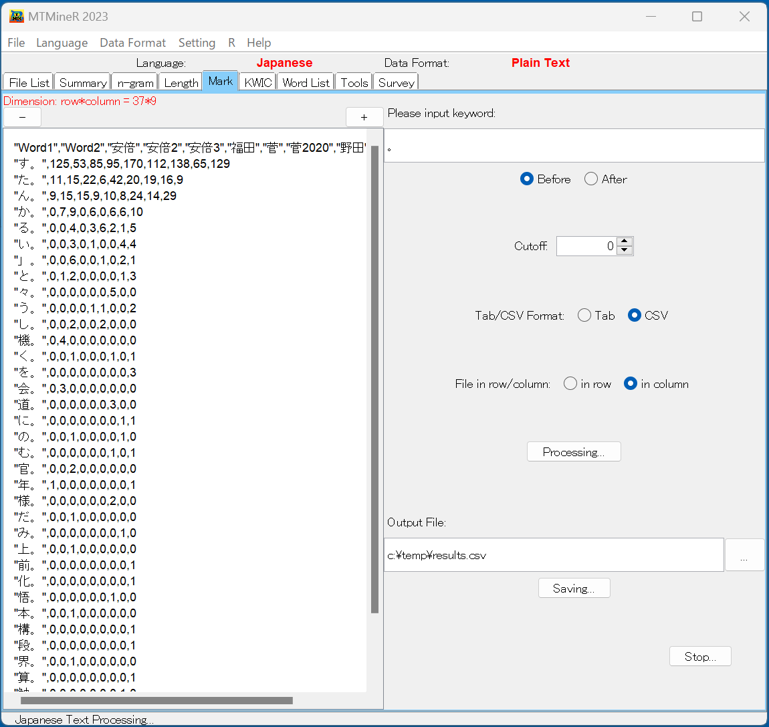
タブMarkでは、ある文字・記号の前後の文字を切り取ったデータを集計する。
「Please input keyword」下の窓に指定の文字或は記号を入力して、当該文字・記号がどの文字の前に付けているかを集計する時、「After」にチェックを入れる。
逆に当該文字・記号がどの文字の後に付けているかを集計する時、「Before」にチェックを入れる。
Go To Top
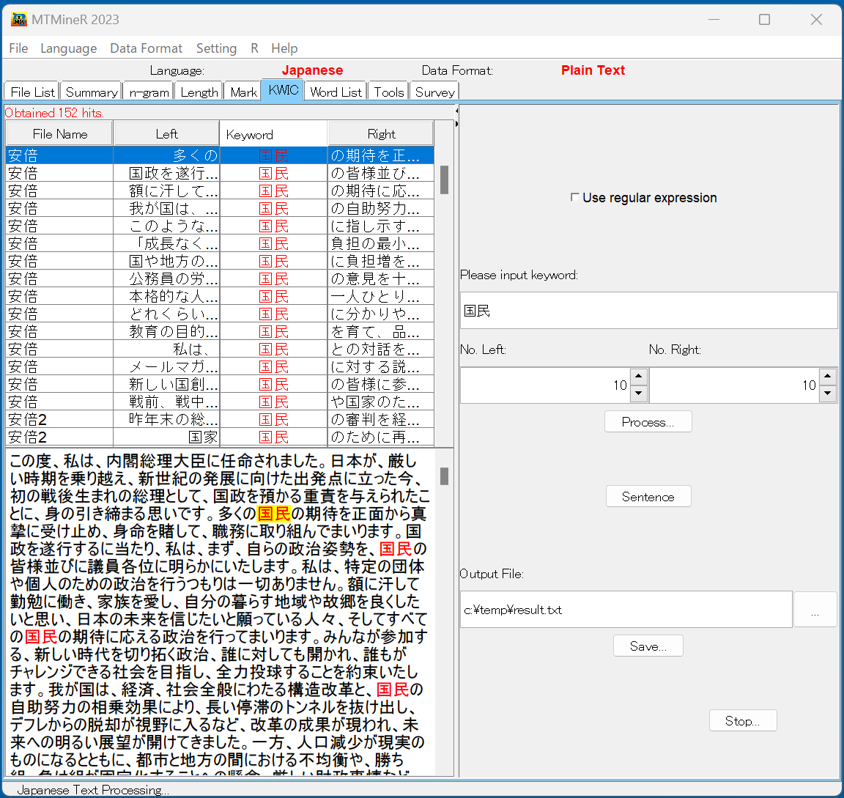
6.KWIC(クウィック検索)
タブ「KWIC」(Keyword in context)では、指定したキーワードについてすべてのテキストから、その前後の文脈を一定の長さで切り取って返す。
「Please input keyword」下の窓に検索したいキーワードを入力し、画面上の「No. Left」と「No. Right」を用いて前後切り取る長さを自由に指定し、ボタン「Process」を押すと、結果が左側に返される。
「Sentence」を押すと、結果は文単位で返される。 返された結果は自由にソートすることができる。
切り取った部分の前後を基準としたソートは、左側の画面上の「Left」或は「Right」の部分をクリックすると降順、昇順に入れ替わる。
返された結果の一行をクリックするとそれが含まれているテキストが左下側の空白欄に返される。
キーワードは正規表現(regular expression)で指定することが可能である。「Use regular expression」にチェックを入れると正規表現によるKWIC検索ができる。
Go To Top
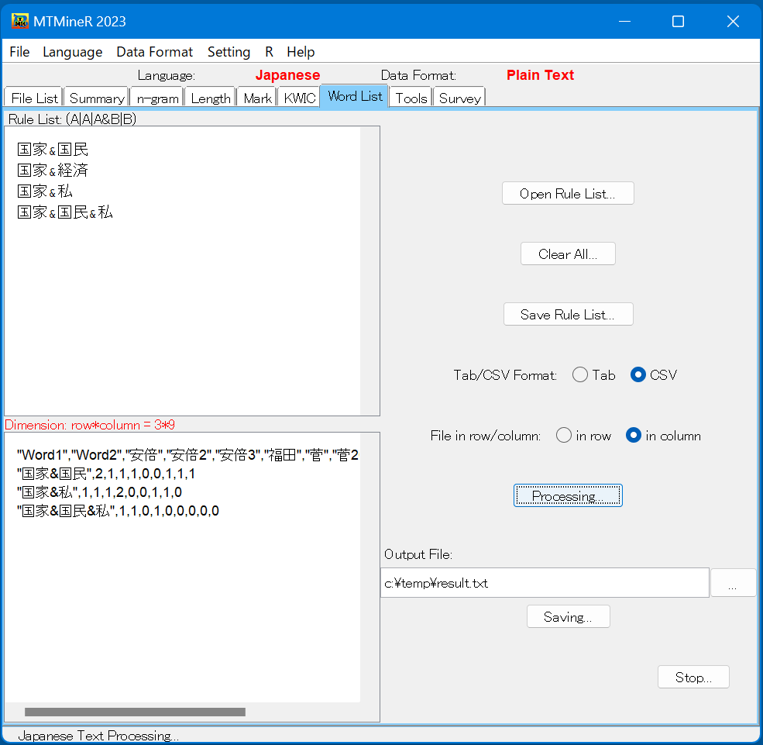
7.WordList
タブ「Word List」では、各自が作成したワードリストに指定している語句をテキストごとに集計する。
ワードリストは画面の左側の「Rule List」の窓に直接記述できる。また、文章エディターで作成したファイルを、ボタン「Open Rule List」から読み込み用いることもできる。
項目の記述は、1行を一つの項目とする。
記述には論理演算を用いることができる。かつ(and)演算は半角の&、また(or)演算は半角の縦棒|を用いる。
「Processing」を押すと、論理演算に満たす文の数が返される。
Go To Top
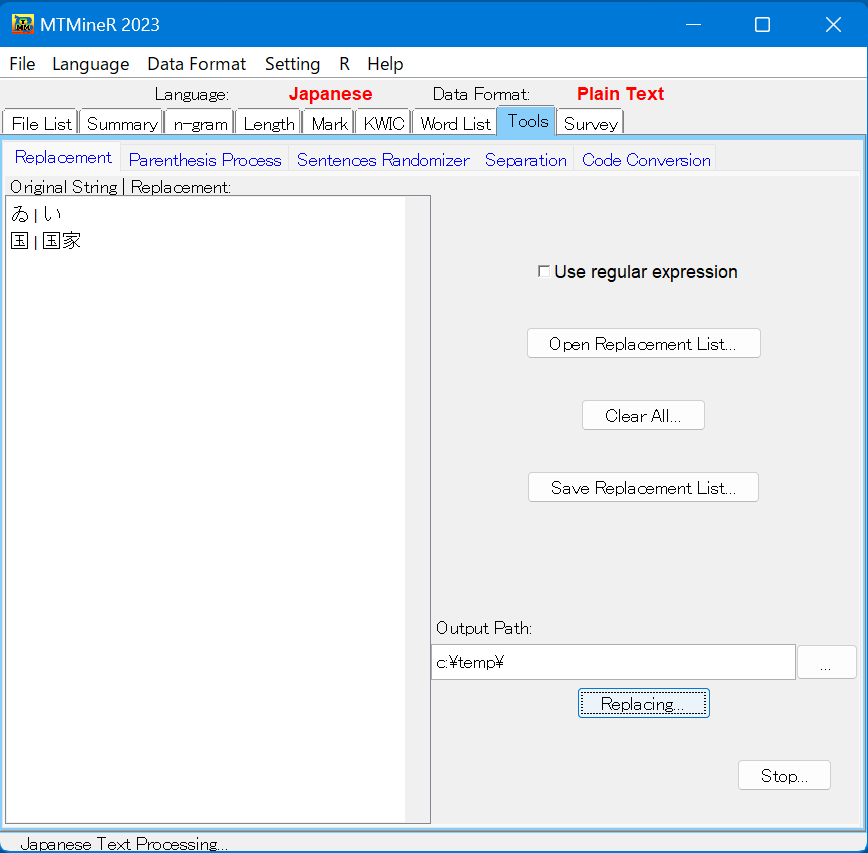
8.Tools(テキストの整形のためのツール)
タブToolsには、「Replacement」、 「Parenthesis Process」、「Sentences Randomizer」、「Separation」、「Code Convension」という五つのサブタブがある。
前の二つはテキストの整形や洗浄に必要な機能である。
- 「Replacement」 「Replacement」では、テキストの中の記号・文字列を置き換える。
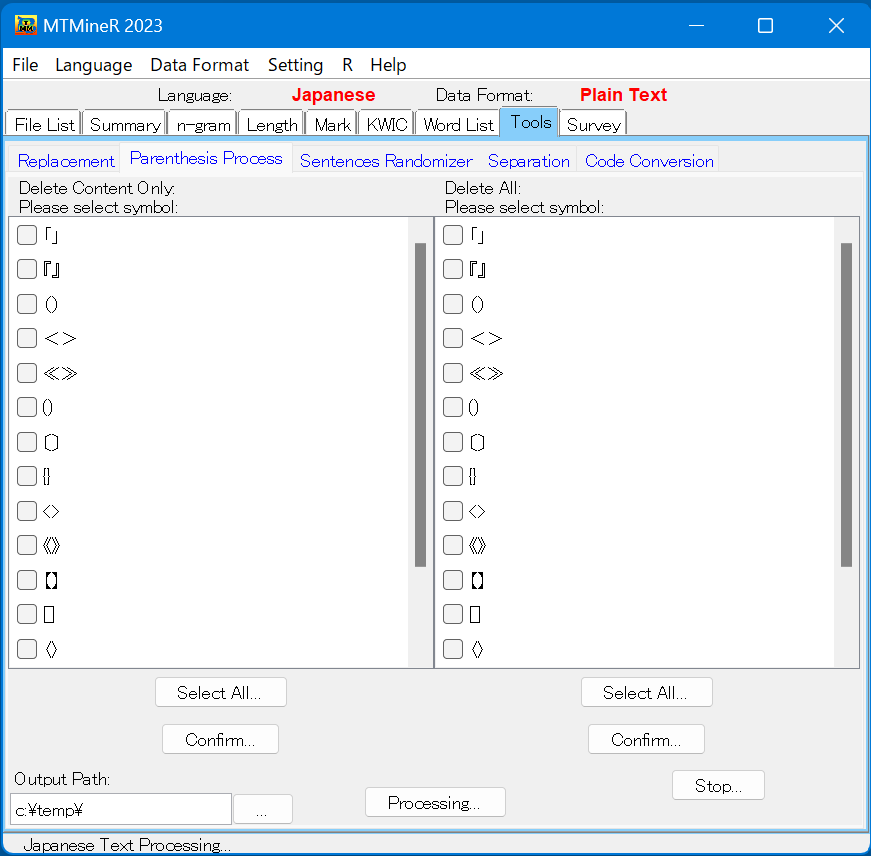
- 「Parenthesis Normalizer」 「Parenthesis Normalizer」では、さまざまな括弧の中のものを削除する機能である。
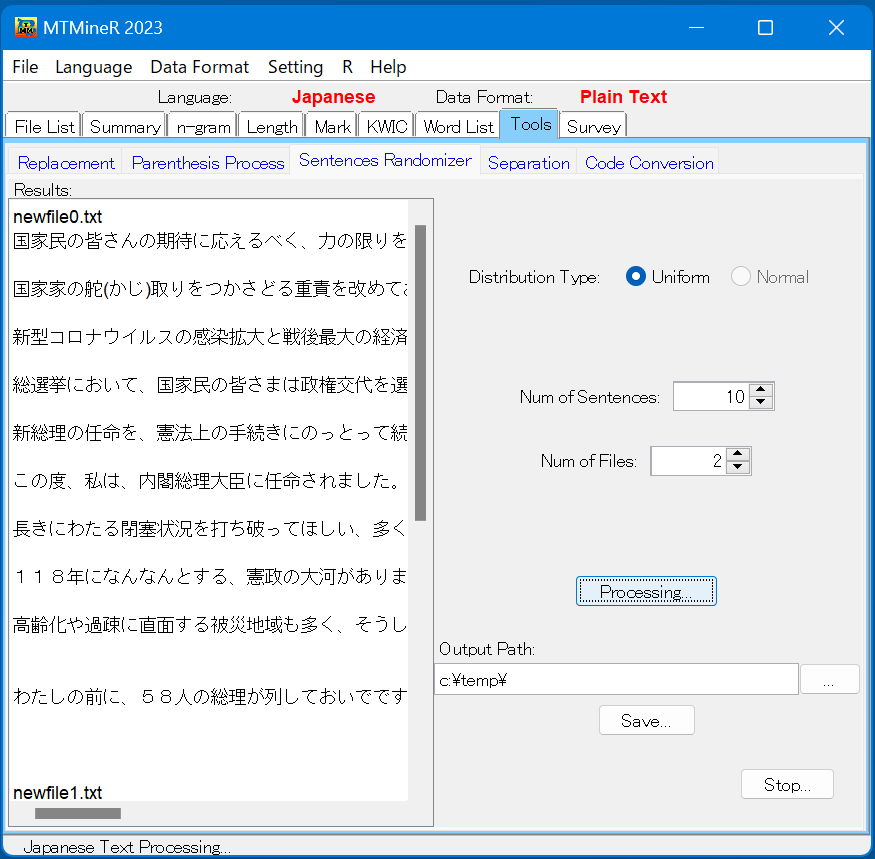
- 「Sentences Randomizer」 「Sentences Randomizer」ではテキストから、ランダムに文を取り出す。
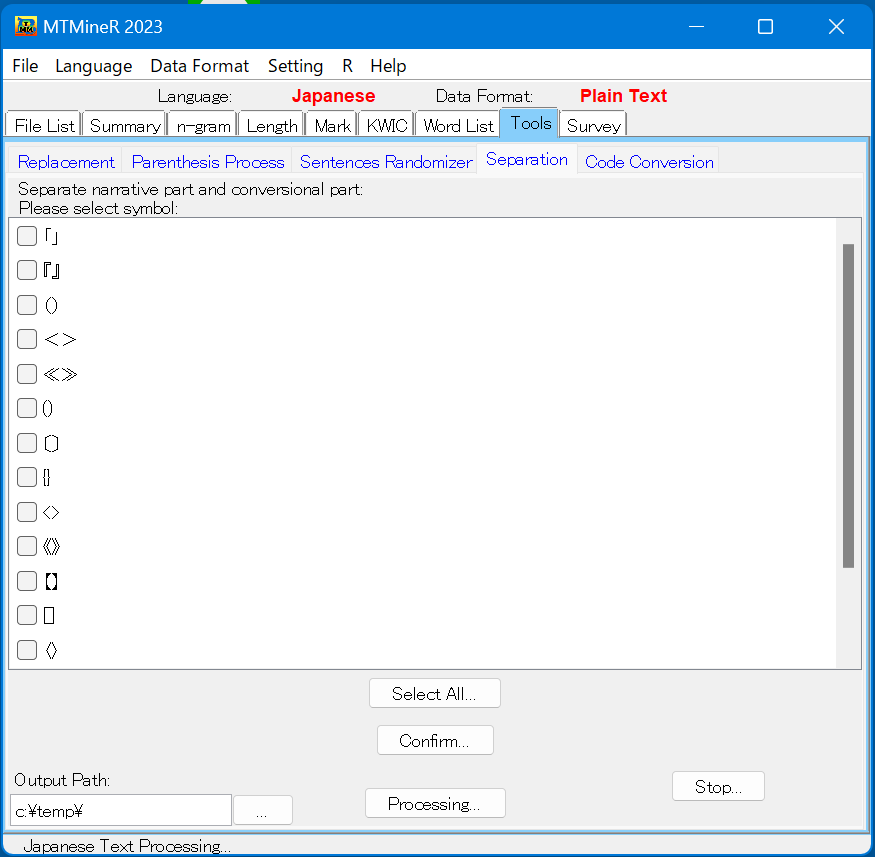
- 「Separation」 「Separation」では、さまざまな括弧の中のものを抽出する機能である。
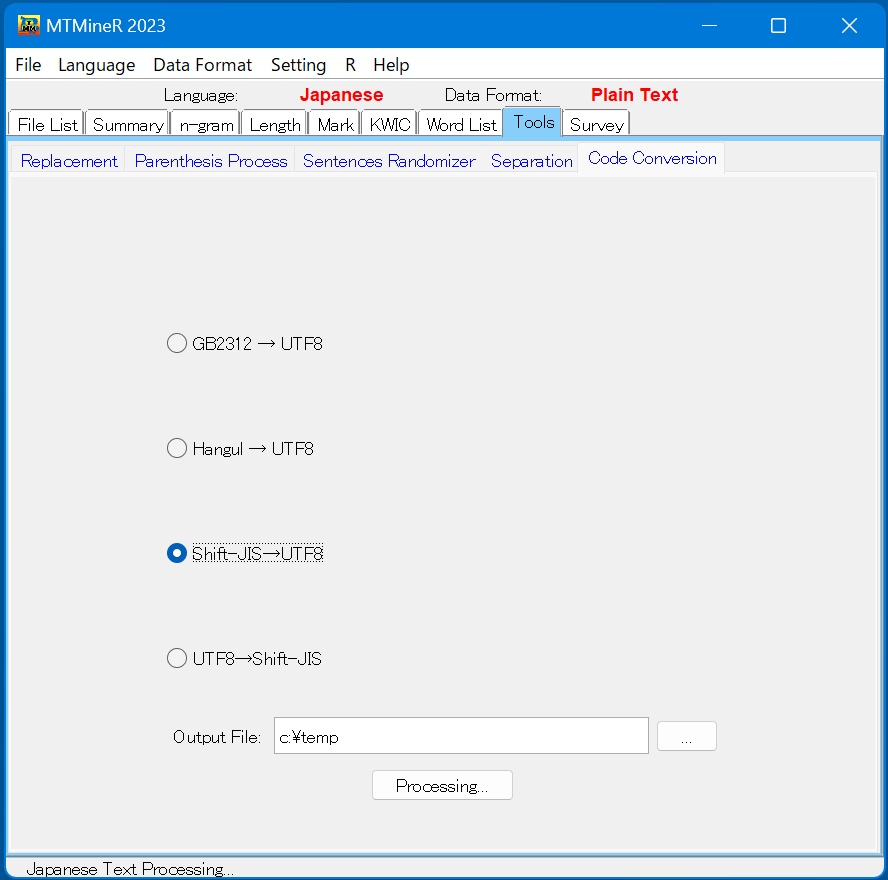
- 「Code Convension」 「Code Convension」では、ファイルの文字コードを変換する機能である。
記述は1行を一項目にする。また、置き換え前と置き換え後の文字列は半角の縦棒|で切り分ける。また、正規表現を用いて記述することもできる。
「Replacing」を押すと、一括変換が行われる。変換したファイルは指定した「Output Path」の中に保存される。
例えば、括弧「」の中の会話文を削除したいときには、左側の「Delete Content Only」の「」をチェックし、その下の確認ボタン「Confirm」押す。
括弧「」とその中身を合わせて削除したいときには、右側の「Delete All」の「」をチェックし、その下の確認ボタン「Confirm」押す。
出力場所を指定した上でボタン「Processing」を押す。
取り出す文の数は画面の右側の「Num of Sentences」で指定できる。
取り出すファイルの数は「Num of Files」で設定できる。
「Processing」を押すと、結果は左側の窓Resultsに返される。
例えば、括弧「」の中の会話文を抽出したいときには、左側の「」をチエックし、その下の確認ボタン「Confirm」押す。
出力場所を指定した上でボタン「Processing」を押す。
例えば、「Shift-JIS→UTF8」は、ファイルの文字コードをShift-JISからUTF8に一括変換できる。
出力場所を指定した上でボタン「Processing」を押すと変換し始まる。