構文解析
構文データ集計については6つのタブが用意されている: 上にある「Ngram Extraction Type」は、「n-gram」と「Pattern」のところでn-gramを集計する時の設定である。「Sentence」を選択する場合は、文ごとにn-gramを集計する。「Text」を選択する場合は、n-gramは文章全体としてにn-gramを集計する。1.File List(データの読み込み)
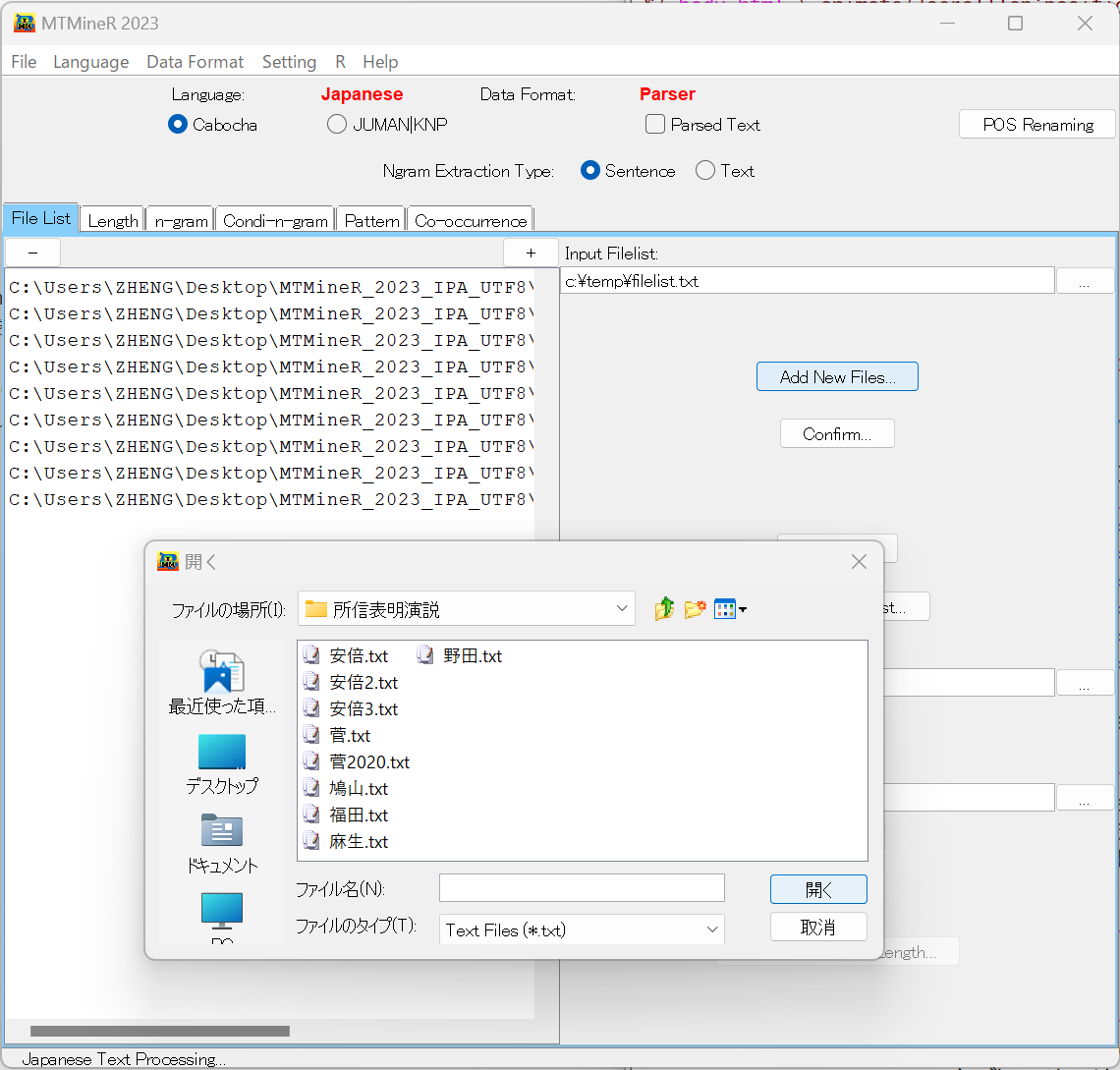
タブFile Listではデータの読み込みを行う。
まず、MTMineRのメニューの「Data Format」から Parserを選択する。
構文解析済みおよび整形したファイルを用いて集計する際はParsed Textのまま行う。平テキストを用いて構文解析を行ったうえでデータを作成したいときにはPlain Textを選択する。
平テキストを用いる際にはCaboChaがインストールされ、パスが通されている環境で行う必要がある。
File Listの右側にある二つ目のAdd New Filesをクリックしテキストファイルを読み込む。読み込みたいファイルを選択し、「開く」をクリックすると選択したテキストがFile Listの左の窓にリストアップされる。
平テキストを選択した場合、POS Renamingのタブをクリックし、Confirmをクリックすると構文解析を行うことができる。この際に赤字で書かれたものを書き換えることで品詞タグをどのように付与するか各自で自由に決めることができる。
Go To Top
2.Length(文節を単位とした長さの分布)
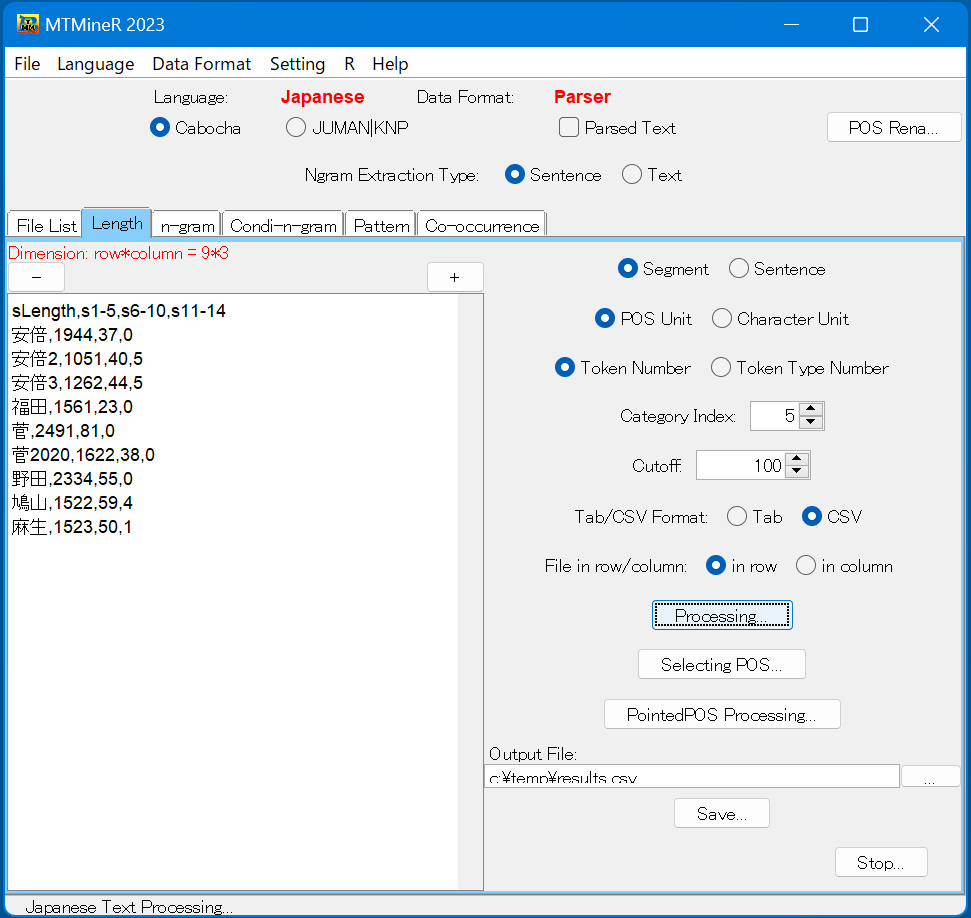
タブ「Length」では、文節を単位とした長さの分布(文節の長さ、文節単位の文の長さ)を集計する。
下図の右側にある選択肢をクリックし、Processingを押すと結果が左側の窓に出力される。
文節の長さはSegment、文節単位の文の長さはSentenceで出力することができ、長さの単位は形態素(POS Unit)、文字(Character Unit)と述べ語数(Token Number)、異なり語数(Token Type Number)が選択可能である。
Category indexには一つの項目にいくつの要素をまとめるかに関する単位を入力する。文字を単位としていないときには一般的には1にする。
Cutoff値は100に設定されている。これは長さが100以上のものは一つの項目にまとめることを意味する。これを変更したい場合は、Cutoffの数字を変えればよい。
出力結果の形式はTab/CSV FormatとFile in row/columnを指定する。Tab formatはデータをタブで区切り、CSV formatはデータをコンマで区切る。File in rowは個体を行で、File in columnは個体を列で表示する。 集計したデータを保存する際には、保存の場所とファイル名前を指定し、Saveをクリックする。
Go To Top
3. n-gram(文節のn-gram)
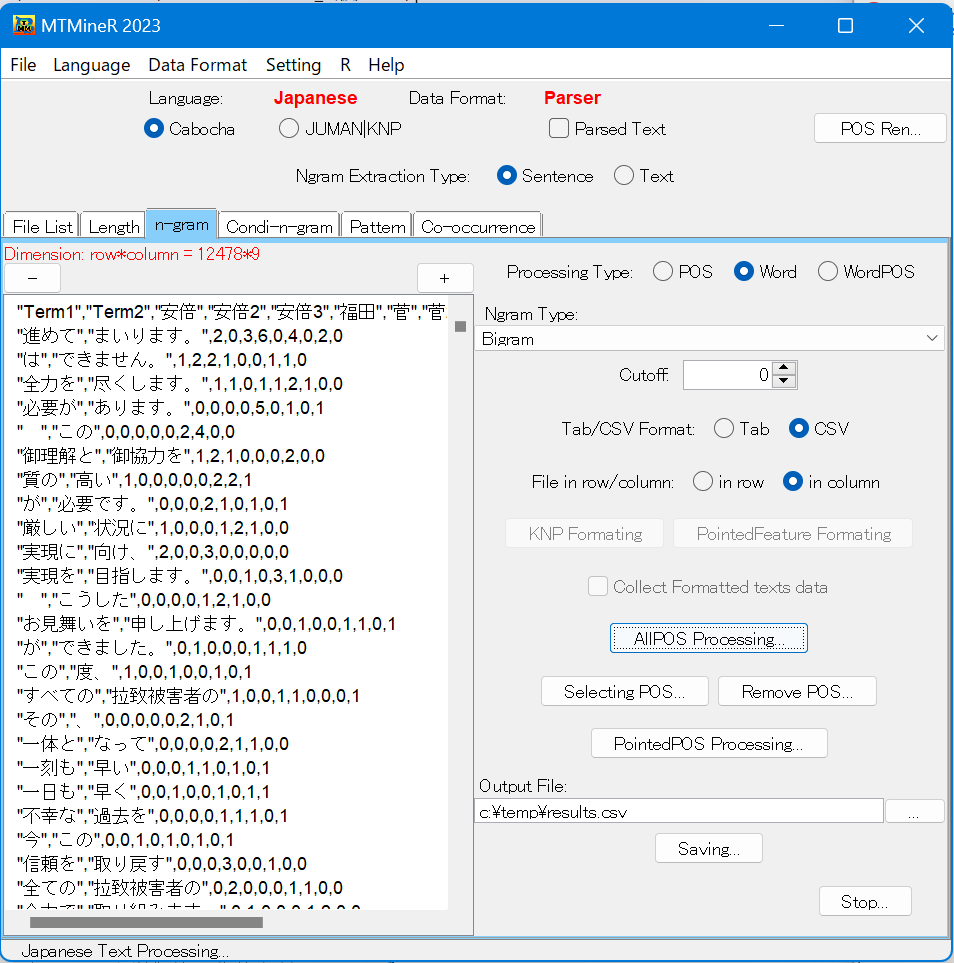
タブ「n-gram」では、文節単位の属性のn-gram、属性付きの文節のn-gram、指定した属性のみを含んだ文節のn-gramを集計することができる。
集計したい形態をProcessing TypeのPOS(文節単位の属性のn-gram)、Word(文節のn-gram)、WordPOS(属性付きの文節のn-gram)から指定する。
Ngram Type下の窓でnを選択する。N-gramとは、集計する際の文節区切りの数である。Unigram(n=1)の場合文節を一つずつ集計し、Bigram(n=2)の場合は二つの文節の組み合わせを一つとして集計する。 選択肢は、Unigram(n=1)、Bigram(n=2)、Trigram(n=3)、Fourgram(n=4)、Fivegram(n=5)、Sixgram(n=6)の六つがある。
Cutoffを用いて集計サイズをコントロールすることができる。デフォルトは100となっており、100以上の頻度のものを表示する。それ以下のものに関してはOTHERSとして一つの項目にまとめられる。
All POS Processingをクリックすると集計結果が左側のResults窓に返される。下側の左図はWord(文節のn-gram)を集計した画面である。
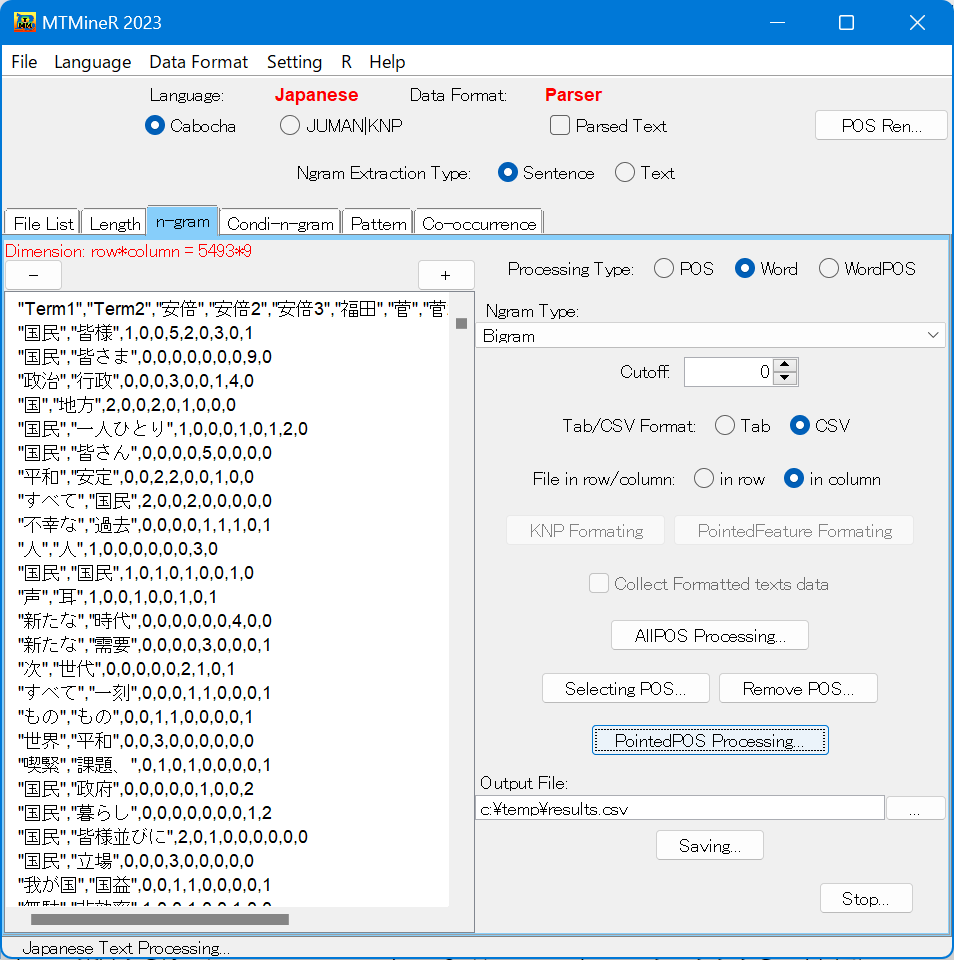
指定した属性のみを含んだ文節のn-gramを集計する際は、All POS Processingではなく、Selecting POSをクリックする。
下図のように指定したい属性(下図では名詞にチェックをいれている)と取り除く属性(下図では助詞を取り除いている)の種類にチェックをいれConfirmをクリックした後にPointed Tag Processingを選択すると集計結果が左側の窓に返される。
Go To Top
4. Condi-n-gram(条件付きの文節のn-gram)
タブCondi-n-gramでは、条件付きの文節のn-gramが集計できる。これは、指定した属性のn-gramの中から一部の属性データを除外したデータを集計する。
下図は名詞を含んだ文節の中から、助詞を取り除いたものである。
まず、Selecting POSをクリックし、指定したい属性を選択し、Confirmをクリックする。次に、Remove POSをクリックし、取り除きたい属性を選択し、Confirmをクリックする。
最後にPointedPOS Processingをクリックすると、左窓に結果が表示される。
デフォルトは、Cutoff100となっており、100以上の頻度のものしか表示されない。100文字以下のものはすべてothersにまとめられる。
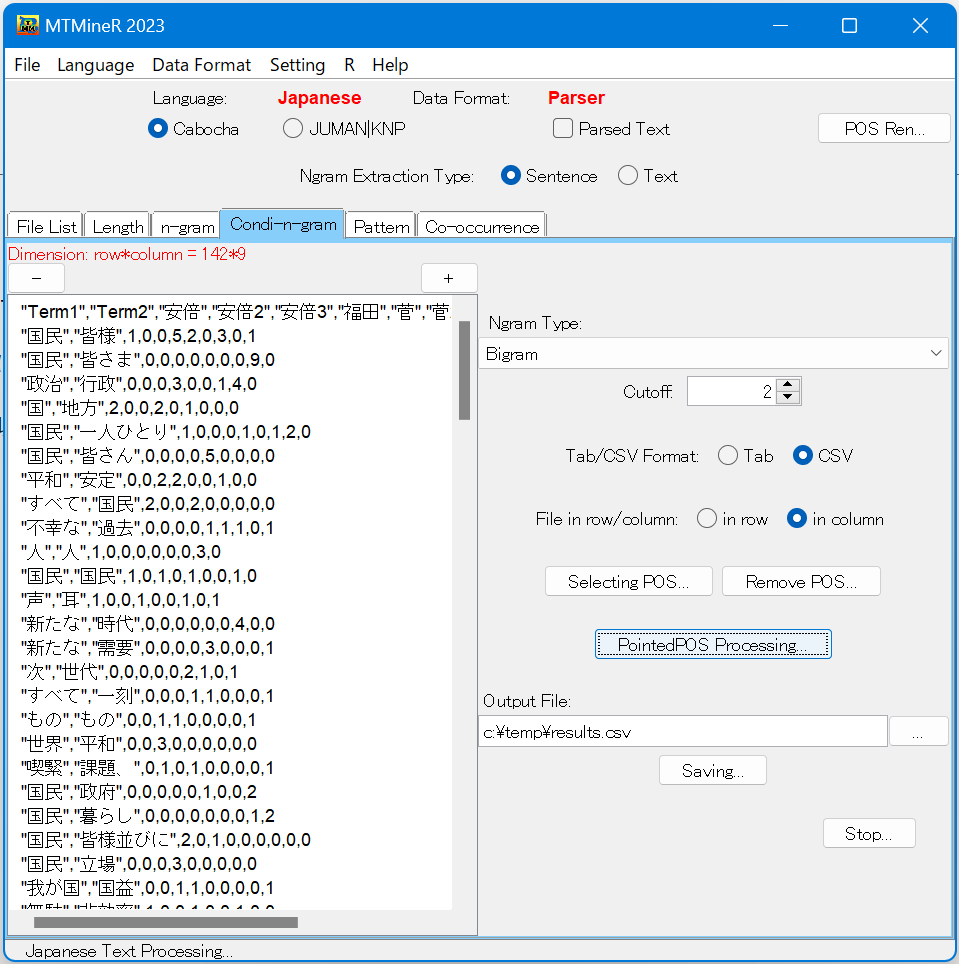
この機能は複合語を含む形態素より長い単位の語句の集計が可能である。例えば,mecabでし「自然言語処理を行う」を形態素解析すると「自然」「言語」「処理」「を」「行う」に分解され、名詞を集計すると「自然」「言語」「処理」が集計される。一方cabochaで文節分解を行うと「自然言語処理を」「行う」に分解される。名詞を含む文節の中から助詞を取り除くことにより「自然言語処理」が一つの項目として集計することができる。
Go To Top
5. Pattern(文節のパターン)
タブ「Pattern」では文節パターンを集計することができる。
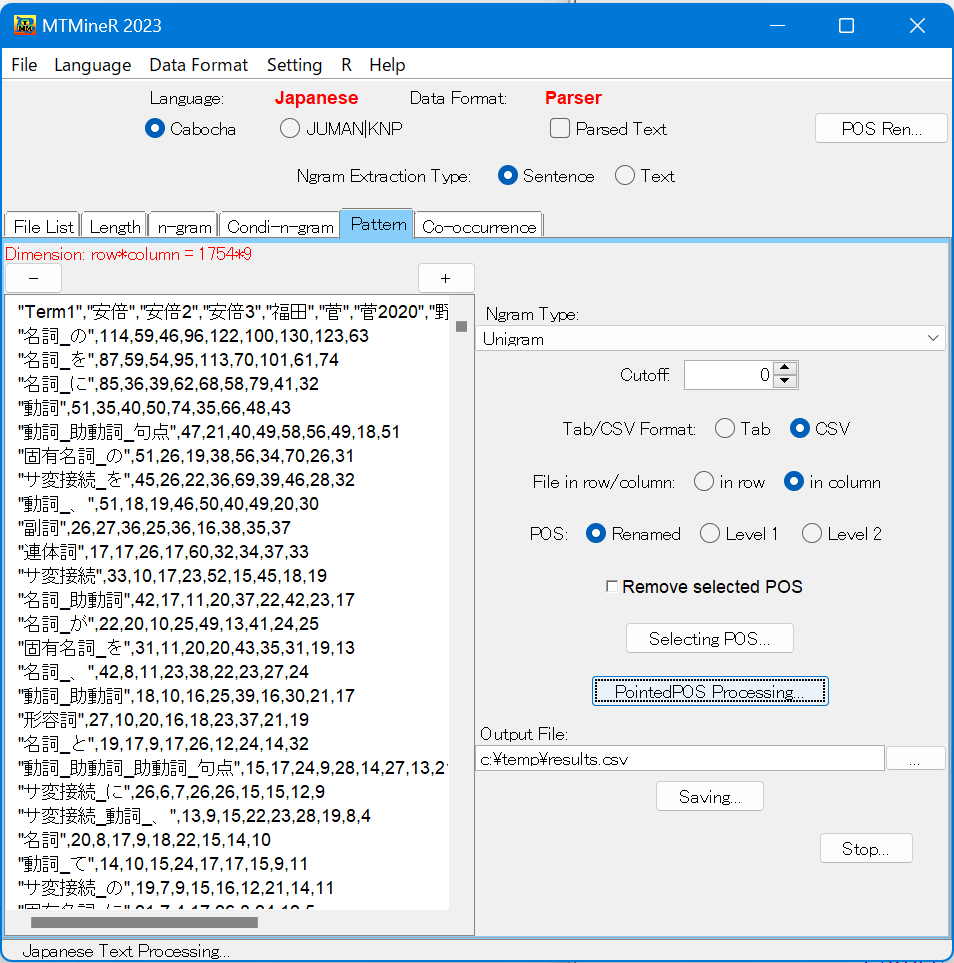
下図は助詞と記号は原型、それ以外は形態素を用いた文節パターンの集計である。(下図の左側)
まず、Renamed を用いるかPOSで形態素解析した結果の何層を用いるかを指定できる。Renamedを選択した場合、自身で自由に設定した赤字の部分の形態素の名前を用いることが可能である。 Level1は第1層、Level2は第2層の情報を用いることができる。
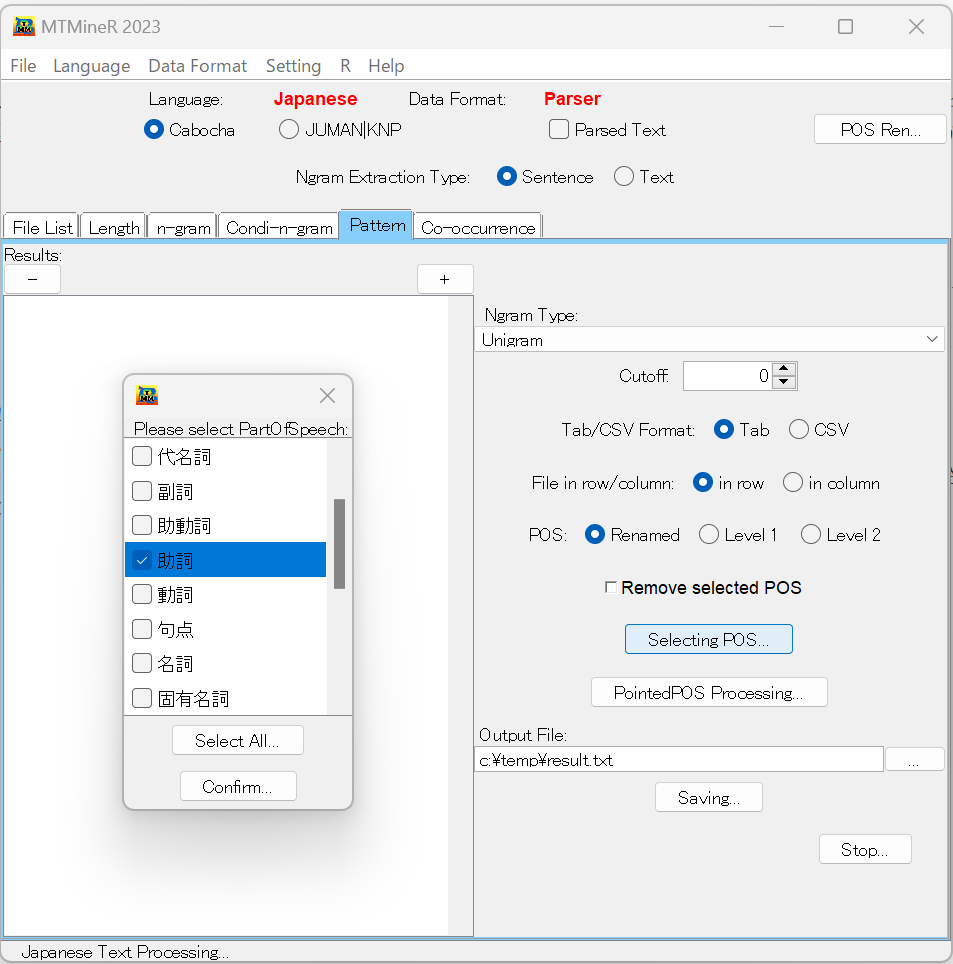
次に、Selecting POSをクリックし、品詞を選択すると、選択された品詞・タグのみが原型(助詞の場合であると、は、がのような単語)で集計される。(下図の真ん中)
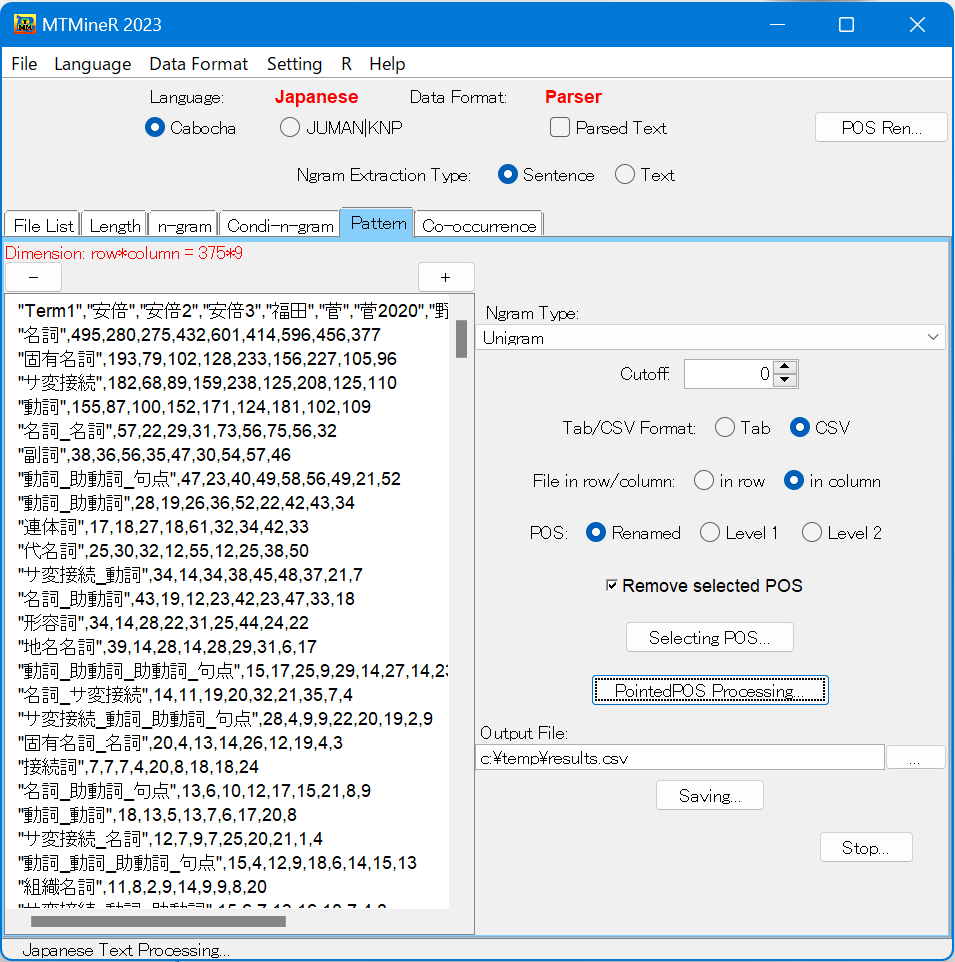
また、Remove selected POSにチェックを入れると、Selecting POSで指定した品詞を除いた条件付のパターンを集計することが可能である(下図の右側)。
Go To Top
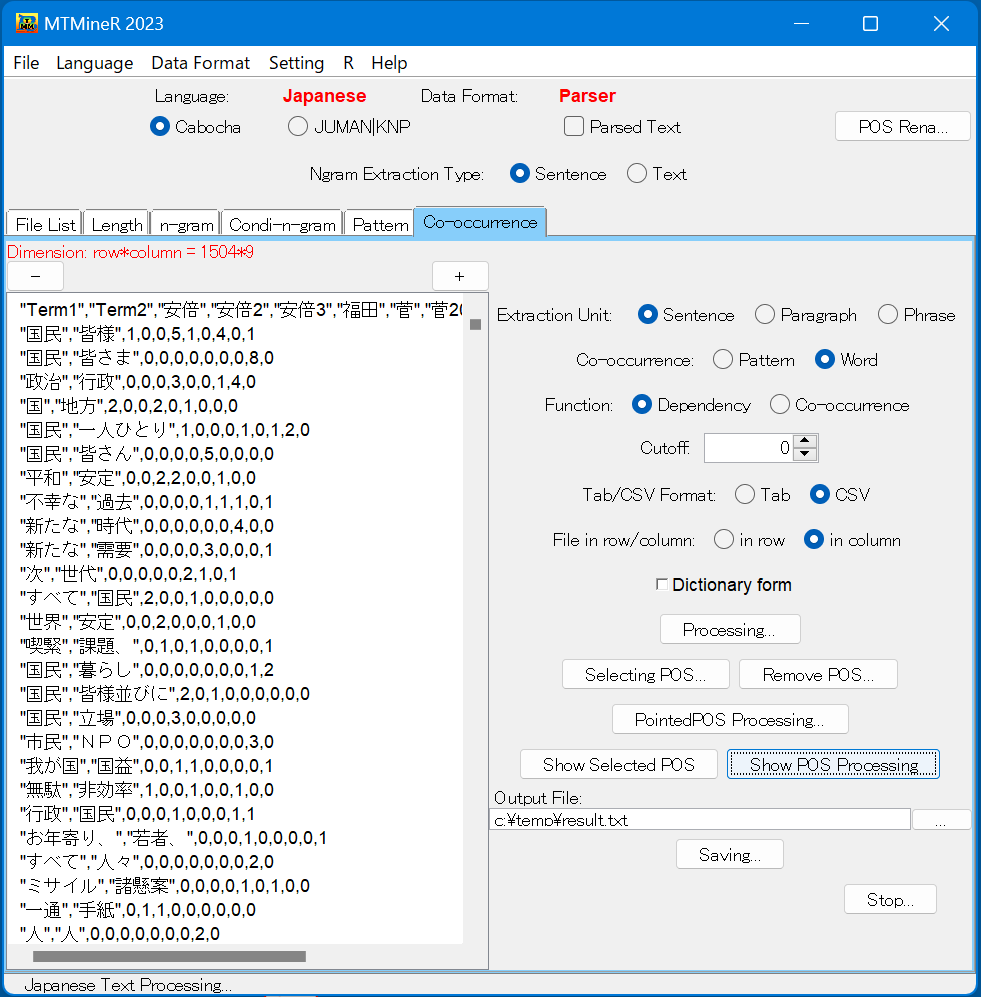
6. Co-occurrence(文節の共起)
タブ「Co-occurrence」では係り受け先を考慮した共起と係り受け関係を無視した共起を集計することが可能である。
「Extraction Unit」は、共起抽出のユニットを指定する。 「Co-occurace」は、Patternではタグ、Wordでは形態素の形式で集計する。 「Function」のDependencyを選択すれば係り受け先を考慮した共起、Co-occurrenceを選択すれば係り受け関係を無視した共起を集計することができる。
Condi-n-gramと同様に「Selecting POS」、「Remove POS」で指定した品詞を除く条件付のパターンを集計することが可能である。
「PointedProcessing」をクリックすると集計結果が左窓に出力される。
「Show Selected POS」で指定した品詞を表示できる。
Go To Top