MTMineRは主に日本語、中国語、韓国語、英語、ドイツ語、フランス語、イタリア語、古代ギリシャ語、ラテン語などのテキスト解析のために作成した。
本システムでは、
データの構造化では平テキストやタグ付きのテキストから頻度を集計し表形式(行列形式) のデータを出力する。
データ統計分析は、集計結果を一旦保存し、各自が使い慣れている統計ツールを用いて分析することもできる。 また、データ解析のフリーソフトRをインストールし、 若干の設定を行うと直接 MTMineR からメニュー操作で用意されているデータ解析の方法を用いることができる。
平テキストは、我々が書いた一般の文章形式を指す。
タグ付きは、平テキストを自由に切り分け、その部分の性質を<>の中に自由にタグを付けたテキストを指す。
ここで、MTMineRを用いて、各言語に対して形態素解析の操作を説明する。各形態素解析器を使う前に環境設定が必要であるため、MTMineR事前準備マニュアルに参考してください。
まず、メニューバーに[language]を選択し、[Data Format]に[Tagged Text]を選択する。
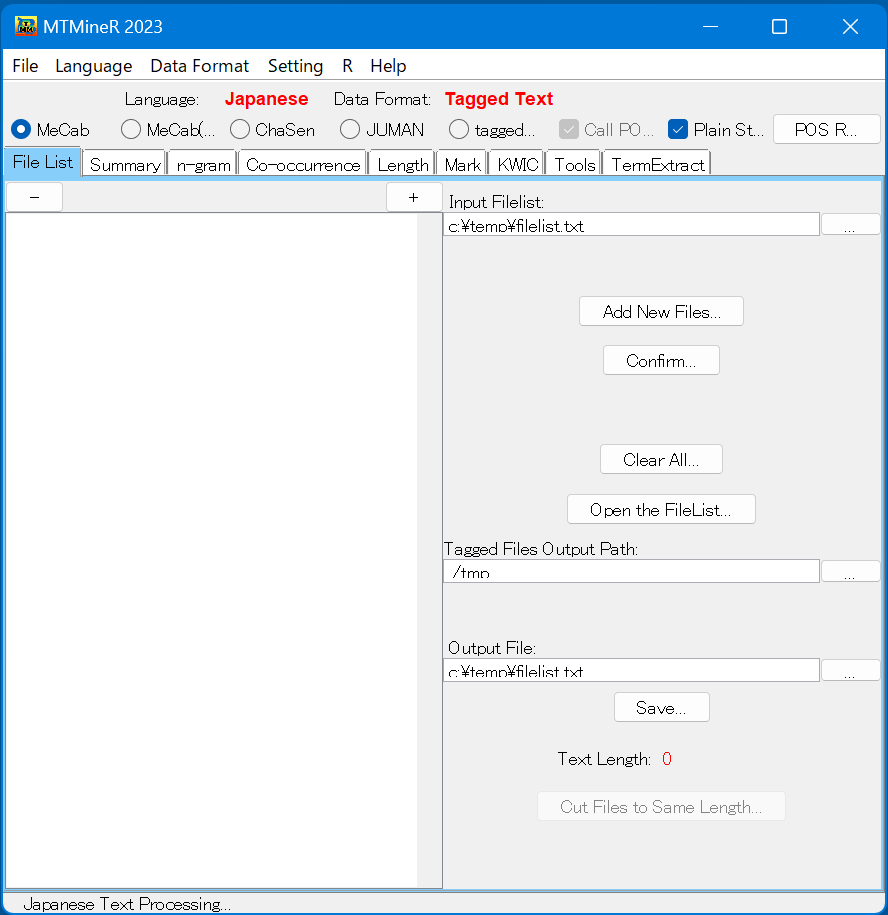
MeCab、ChaSen、JUMANによって形態素解析を行ったテキストを読み込み処理するときには、 図に示す画面の上部の三種類の形態素解析器の名前にラジオボタンを選択する。
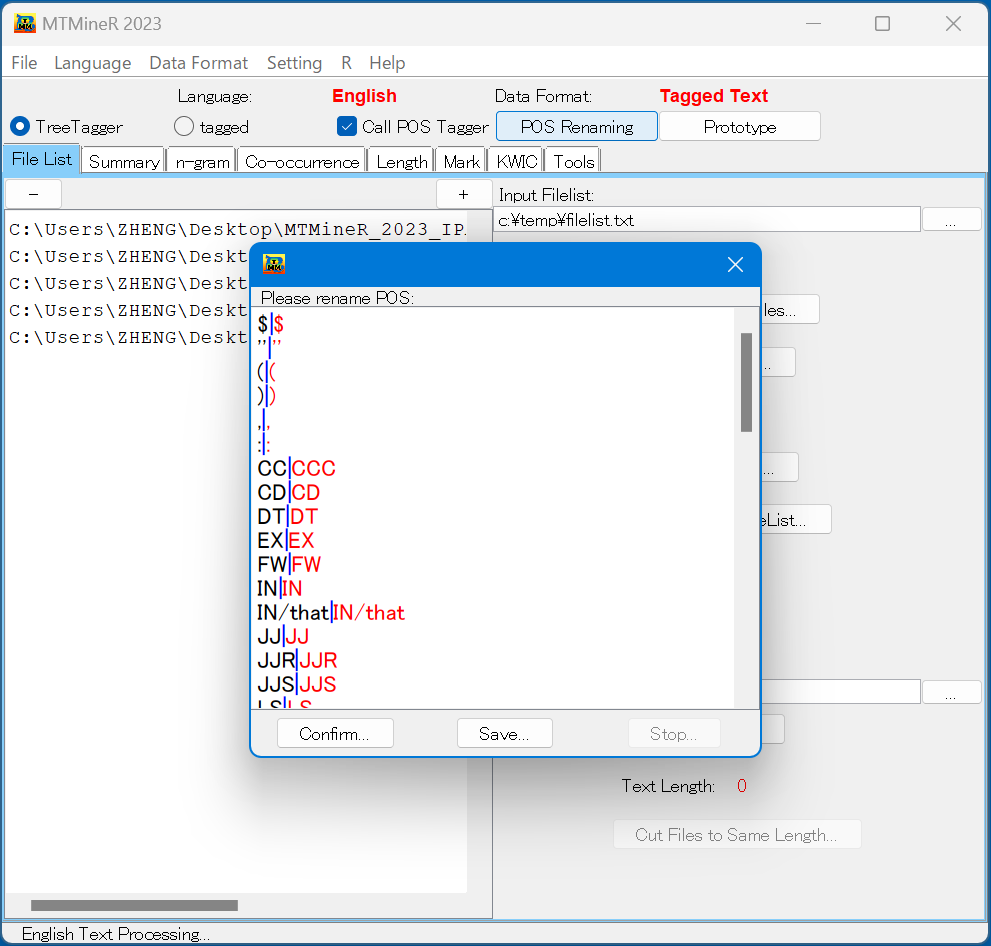
形態素解析器を選択し、さらに[POS Renaming]ボタンを押し、品詞の命名を行う。ボタン [POS Renaming]を押すと品詞を命名する窓が開かれる。
黒字は形態素解析器の結果であり、青色縦棒の右の赤文字は自由に書き換えられる形態素の属性である。属性の命名が終わったら確認ボタン [Conform]を押す。
[Plain Style]をチェックすると、原形が集計される.
これで、日本語形態素解析が終った。形態素解析結果を[tmp]ファイルに保存している。
Go To Top
本システムでは、
- 日本語の形態素解析はJUMAN、ChaSen、MeCab、MeCab(辞書追加)、構文解析は CaboCha、
- 中国語の形態素解析はJieba、
- 英語、ドイツ語とフランス語などの形態素解析はTreeTagger
データの構造化では平テキストやタグ付きのテキストから頻度を集計し表形式(行列形式) のデータを出力する。
データ統計分析は、集計結果を一旦保存し、各自が使い慣れている統計ツールを用いて分析することもできる。 また、データ解析のフリーソフトRをインストールし、 若干の設定を行うと直接 MTMineR からメニュー操作で用意されているデータ解析の方法を用いることができる。
平テキストは、我々が書いた一般の文章形式を指す。
タグ付きは、平テキストを自由に切り分け、その部分の性質を<>の中に自由にタグを付けたテキストを指す。
ここで、MTMineRを用いて、各言語に対して形態素解析の操作を説明する。各形態素解析器を使う前に環境設定が必要であるため、MTMineR事前準備マニュアルに参考してください。
日本語
MeCab、ChaSen、JUMAN がインストールされ、パスが通されている環境では、 平テキストを読み込み、MTMineRでメニュー操作により形態素解析を行い、タグを付け集計を行うことが可能である。まず、メニューバーに[language]を選択し、[Data Format]に[Tagged Text]を選択する。
MeCab、ChaSen、JUMANによって形態素解析を行ったテキストを読み込み処理するときには、 図に示す画面の上部の三種類の形態素解析器の名前にラジオボタンを選択する。
- タブの命名
形態素解析器を選択し、さらに[POS Renaming]ボタンを押し、品詞の命名を行う。ボタン [POS Renaming]を押すと品詞を命名する窓が開かれる。
黒字は形態素解析器の結果であり、青色縦棒の右の赤文字は自由に書き換えられる形態素の属性である。属性の命名が終わったら確認ボタン [Conform]を押す。
[Plain Style]をチェックすると、原形が集計される.
これで、日本語形態素解析が終った。形態素解析結果を[tmp]ファイルに保存している。
Go To Top
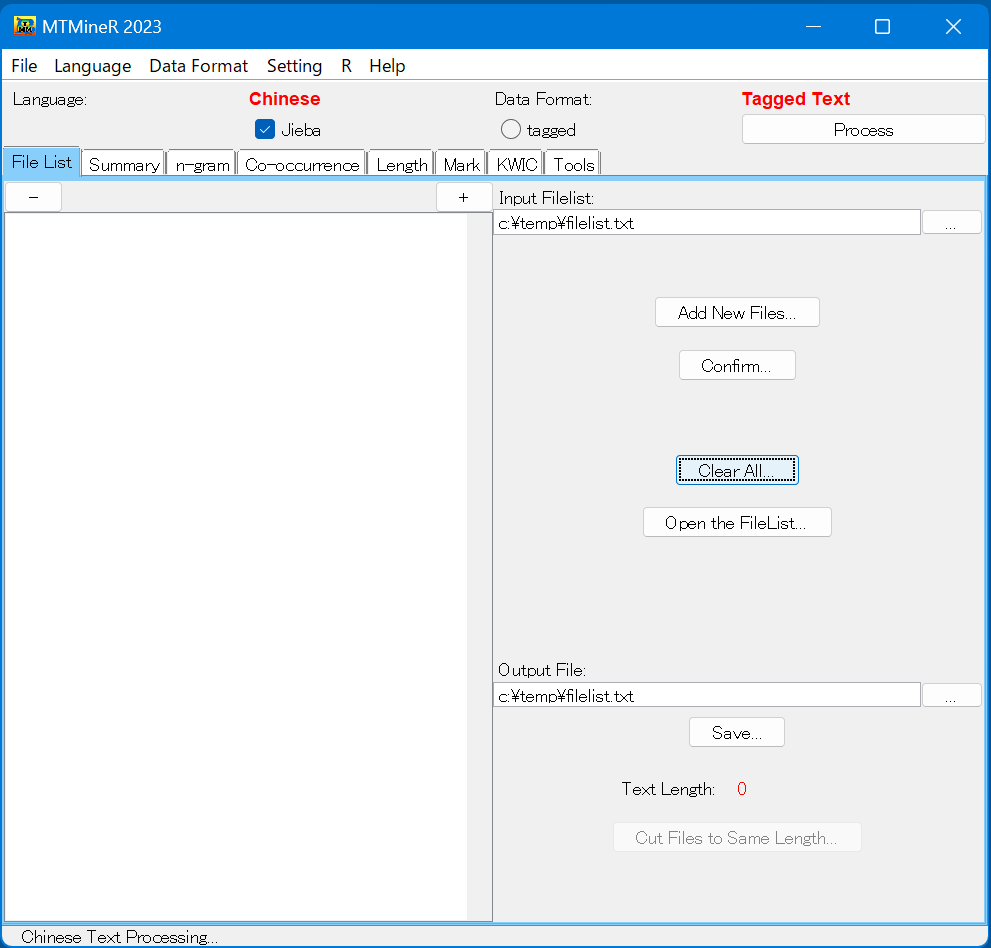
中国語
中国語の形態素解析はJiebaを使っている。パスを通す必要がない。しかし、テキストはUTF-8で保存する必要がある。また、ファイル名についてアルファベットしか認識できない。
Go To Top
英語など
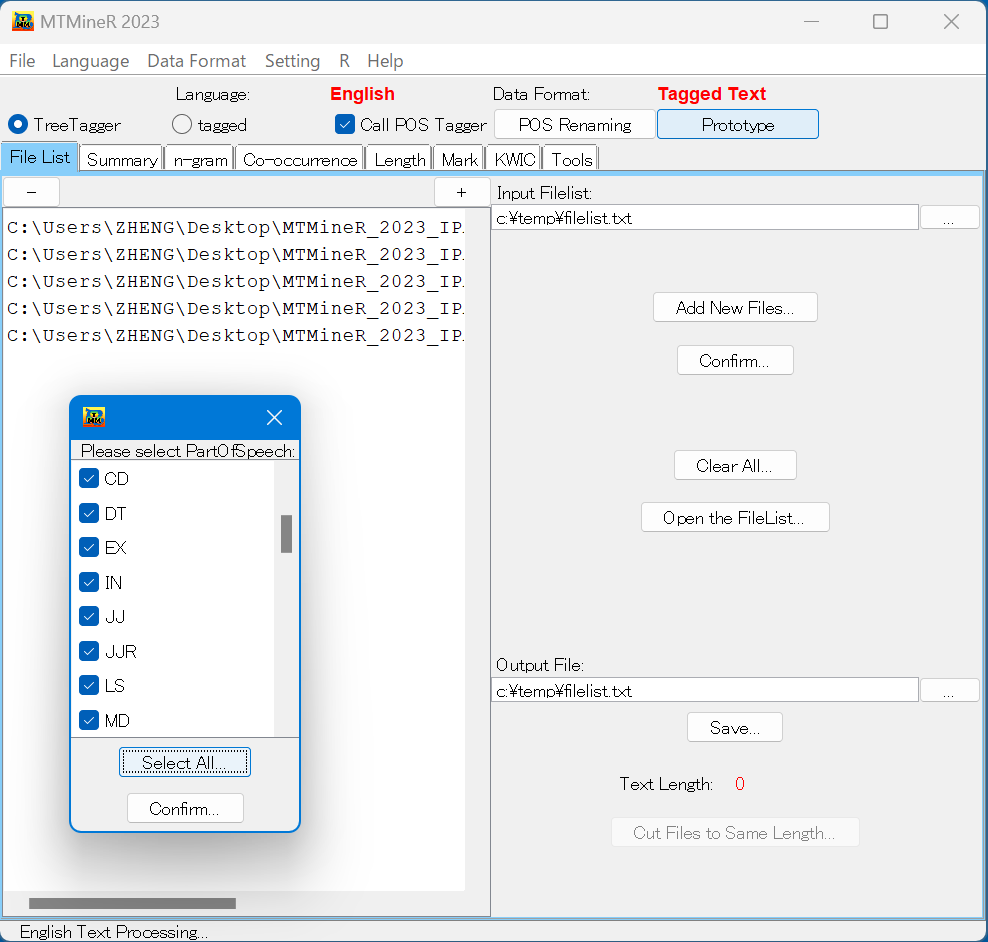
英語、ドイツ語とフランス語などの形態素解析は共にTreeTaggerを借用する。操作は同じであるので、ここで、英語を例として説明する。[treeTagger]、[Call POS Tagger]を選択してから、[POS Renaming]を押し、日本語と同じくタグの名前を変更できる。 [Confirm]を押すと、形態素解析を完了する。
さらに,[Prototype]を押すと、原形で集計する品詞を指定できる.
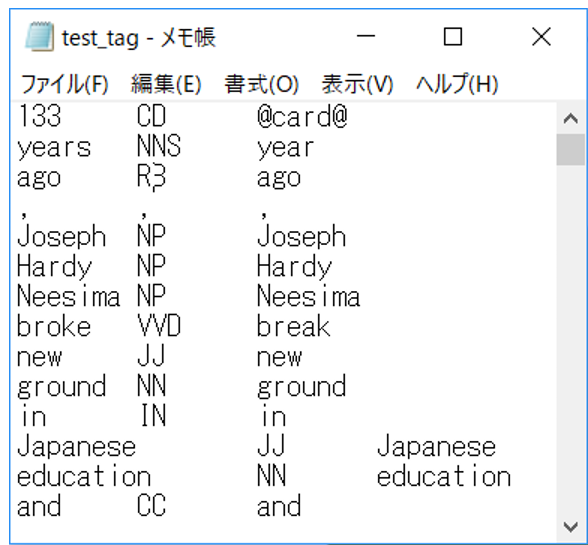
TreeTaggerの形態素解析結果を下の図に示している。第1列はテキストの中に用いた単語、第2列はタグ、第3列は単語の原型である。
[Prototype]を選択しないまま形態素解析する結果は、[テキストの中に用いた単語/タグ]になっている。一方、[Prototype]を選択すると[単語の原型/タグ]という結果になる。
タグの情報はTreeTagger公式サイトを参考してください。
Go To Top