MTMineRの概要
MTMineR(Multilingual Text Miner with R;エム・ティ・マイナー)とは,テキスト型データを構造化して集計し,Rを用いて統計的に分析するソフトウェアである.MLTPを高機能化したバージョンである.文学作品・アンケートの自由記述・新聞記事などさまざまなテキストを処理し,データを集計することができる.テキストの統計的解析を勉強する方々のため,無償で本ツールを公開する.ただし,著作権を放棄することではない. MTMineRでは日本語,中国語,韓国語,英語,ドイツ語とフランス語等のデータを扱うことができる.データの構造化では平テキストやタグ付きのテキストから頻度を集計し表形式(行列形式)のデータを出力する.データの統計分析は,各自が使い慣れている統計ツールを用いることができるが,MTMineRは集計したデータを直接メニュー操作でデータ解析ソフトRで分析することもできる.
MTMineRの概略図を次に示している(日本語を例とする)
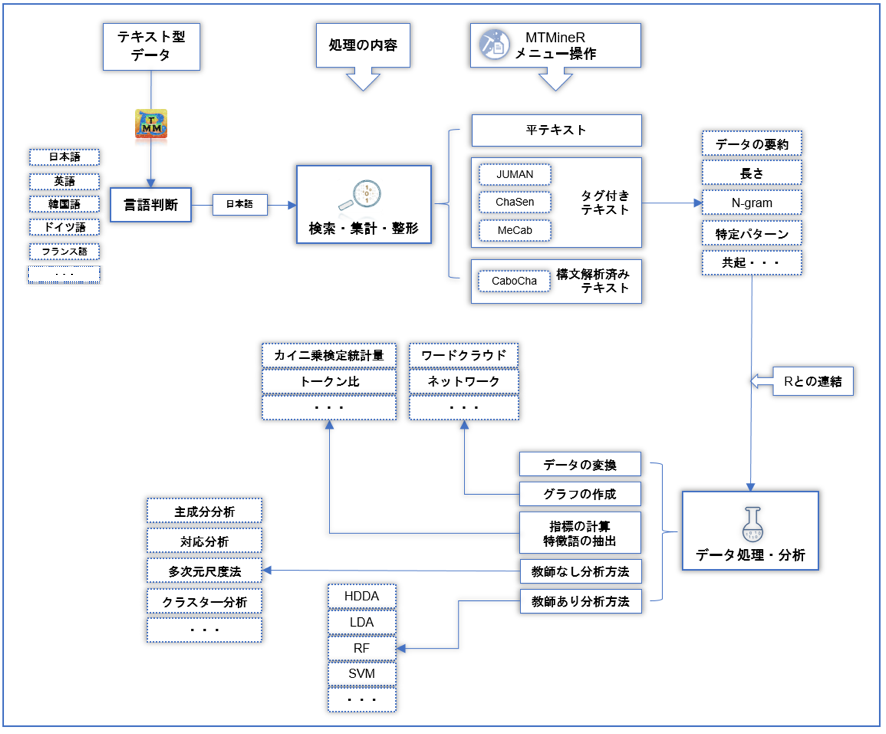
MTMineRの機能
データの検索・集計・整形のサポート機能
- 平テキスト
- タグ付きテキスト
- 構文済みテキスト
データの処理と分析機能
- データの変換
- グラフ作成
- 指標の計算と特徴語の抽出
- 教師なしの分析方法
- 教師ありの分析方法
平テキストの要約(ファイルのサイズ,文字数,文の数,漢字数,平仮名数,カタカナ数,ローマ字の数,数値の数,全角文字の数,半角文字の数),文字・記号のn-gram(n=1,…,6),単語・文などの長さの分布,指定した要素の前後のパターンの集計,KWIC検索やテキストの前処理などの機能がある.
形態素解析済みのテキストにおけるデータの構造化:データの要約(ファイルのサイズ,延べ語数,異なり語数,片仮名単語数,ローマ字単語数など),タグのn-gram,タグ付きの要素のn-gram,タグ単位の要素の長さの分布(文の長さ,タグ区切りの要素の長さなど),指定した要素の前後のパターンなどの集計,タグ単位のKWIC検索,タグ付きデータの一括整形処理など機能がある.
構文解析済みのテキストにおけるデータの構造化:文節を単位とした長さの分布(文節単位の文の長さ,文節の長さ),文節のn-gram,条件付きの文節のn-gram,文節の共起(係り受け関係を無視した共起,係り受け先を考慮した共起),文節のパターンなどのデータを集計する機能がある.
構造化したデータセットはcsv形式とタブ区切り形式で保存し,データ解析・データマイニングツールを用いて分析を行うことができる.本システムではメニュー操作でデータ処理や解析を行うGUI環境を備えている.メニュー操作による主な機能は,データの処理・加工,データの視覚化,指標の計算と特徴語の抽出,教師なしの分析方法,教師ありの分析方法に分けられる.
分析方法によって集計した度数データをテキストの長さに依存しない相対頻度に変換して用いることが必要である.MTMineRでは行あるいは列の合計に基づいた比率の変換,データの標準化,行列の転置機能が設けられている.
データの視覚化ワードクラウド,折れ線グラフ,Zipfの法則とグラフ,ネットワークグラフを作成する.
カイ二乗検定統計量,尤度比検定統計量,カルスカル・ワリス検定統計量,ランダムフォレストの正解率,ジニ分散指標などを用いた特徴語抽出機能やローカルTF-IDF,グロバルTF-IDなど10種類の重み計算,トークン比やYullのK特性値など数種類の語彙の豊富さ指標の計算機能が実装されている.
主成分分析,対応分析,多次元尺度法,k-平均法,階層的クラスタリング法,トピックモデルなどの教師なしの分析の環境が備えている.クラスター分析,多次元尺度法などに用いる距離としてユークリッド距離,SKLD距離,対称的カイニ乗距離など八種類の距離が用意されている.
線形判別,K-近傍法,決定木,ランダムフォレスト,SVM,HDDAが実装されている.