特徴語抽出とグラフ作成
特徴語の抽出は複数のテキストの間、複数のテキストのグループ間に特徴となる要素の候補を検出る。複数のテキストのグループ間の特徴語抽出を行うためには、テキストをグルーピングすることが必要である。グルーピングの指定は、 Please enter groups separating by commasの下の窓に記述する。連番の整数はa:bのように、始まる整数と終わる整数を半角のコロン記号「:」でつなげる。連番ではない場合は、c()の中に番号をカンマで区切り記入する。例えば、テキスト1,3,5が一つグループ、2,4,6が一つグループの場合は、c(1,3,5),c(2,4,6)のように記入する.テキストの番号を用いてグルーピングを指定したら、それに対応するグループの名前を記述する。グルーピングの指定は、 Please enter groups separating by commasの下の窓に記述する。連番の整数はa:bのように、始まる整数と終わる整数を半角のコロン記号「:」でつなげる。連番ではない場合は、c()の中に番号をカンマで区切り記入する。テキストの番号を用いてグルーピングを指定したら、それに対応するグループの名前を記述する。特徴語を抽出する方法は現段階では以下の方法が実装されている。それぞれの方法の詳細に関しては画面上の Help に説明されている。
- ●Chi-square(カイニ乗統計量)
- ●Likelihood Ratio(尤度検定統計量)
- ●Mean Accuracy(RandomForestの中のMeanDecreaseAccuracy)
- ●Mean Gini(RandomForestの中のMeanDecreaseGini)
- ●Mahalanobis' Distance(マハラノビス距離)
- ●Kruskal-Wallis(クラスカル・ウォリス検定統計量)
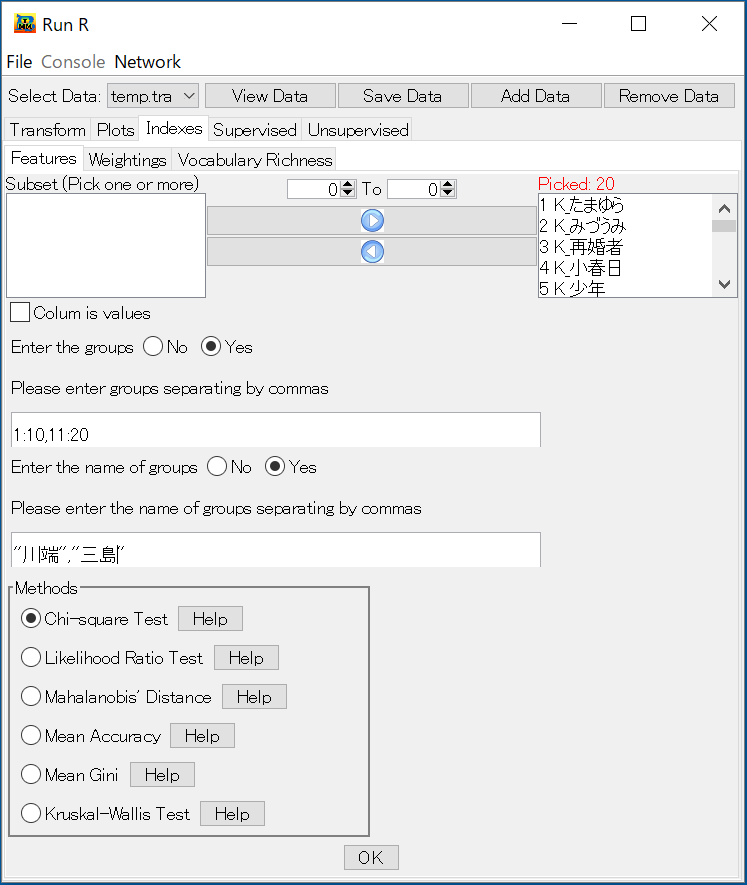
上のグラフのようにラジオボダンを指定し、[OK]ボタンを押すと選択された方法で計算する。計算が終わると結果を保存するファイルの名前を知らせると当時にグラフの作成に関するメッセージボックスが開かれる。グラフ作成を選択すると下のような画面が開かれる。 グラフのタイトル、色、グラフの周辺のマージン、ラベルの文字列の方向を指定し[OK]ボタンを押すと棒グラフが作成される。グラフ作成画面の Scatterplotを指定すると選択された変数の散布図、あるいは対散布図が作成される。
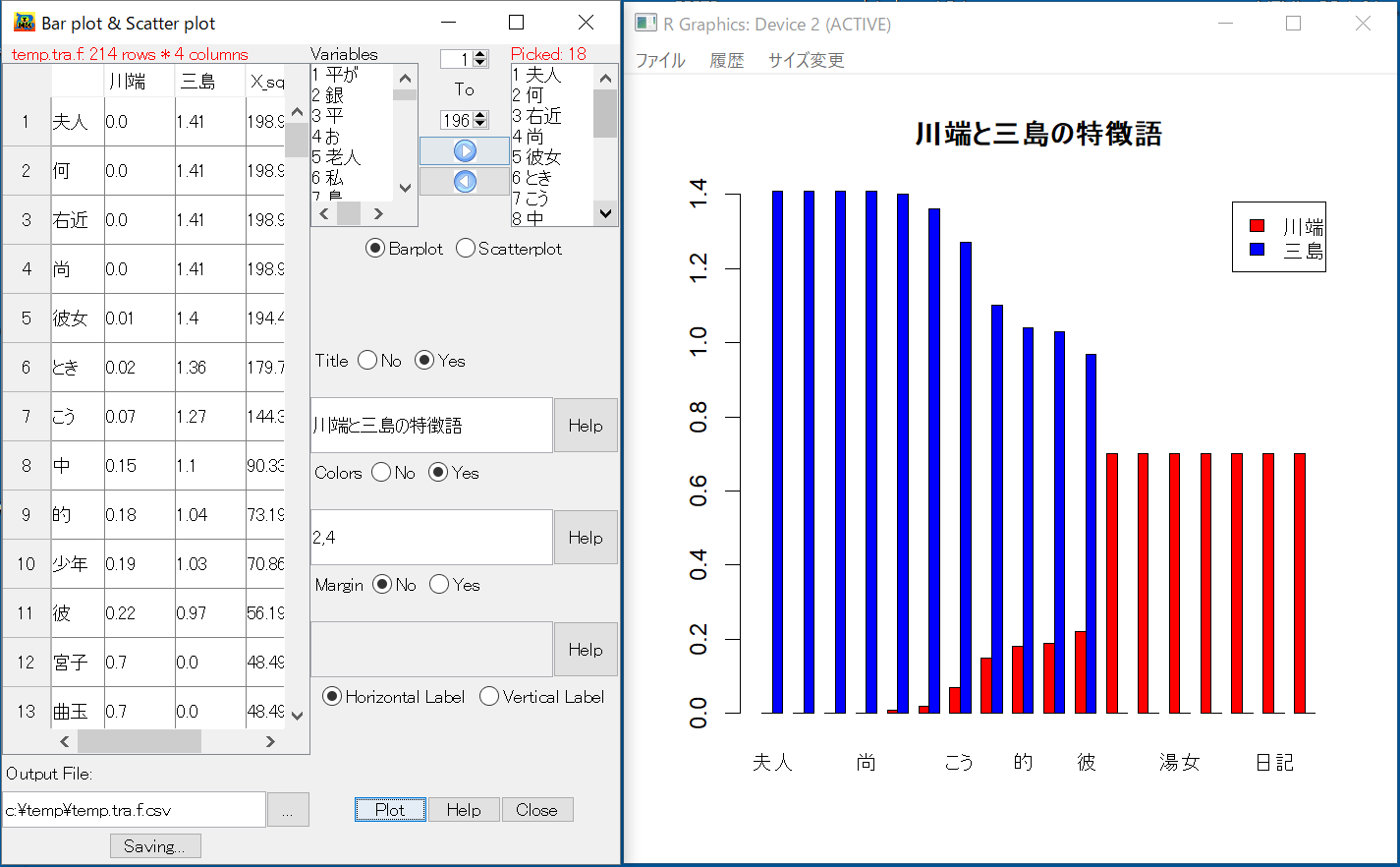
注: グラフのラベルを縦にし、全部表示できるような画面に入れ替えてください。
サブタブ Weightings では、エントロピー(entropy)やTF-IDFなどの 10種類の重みを計算する。
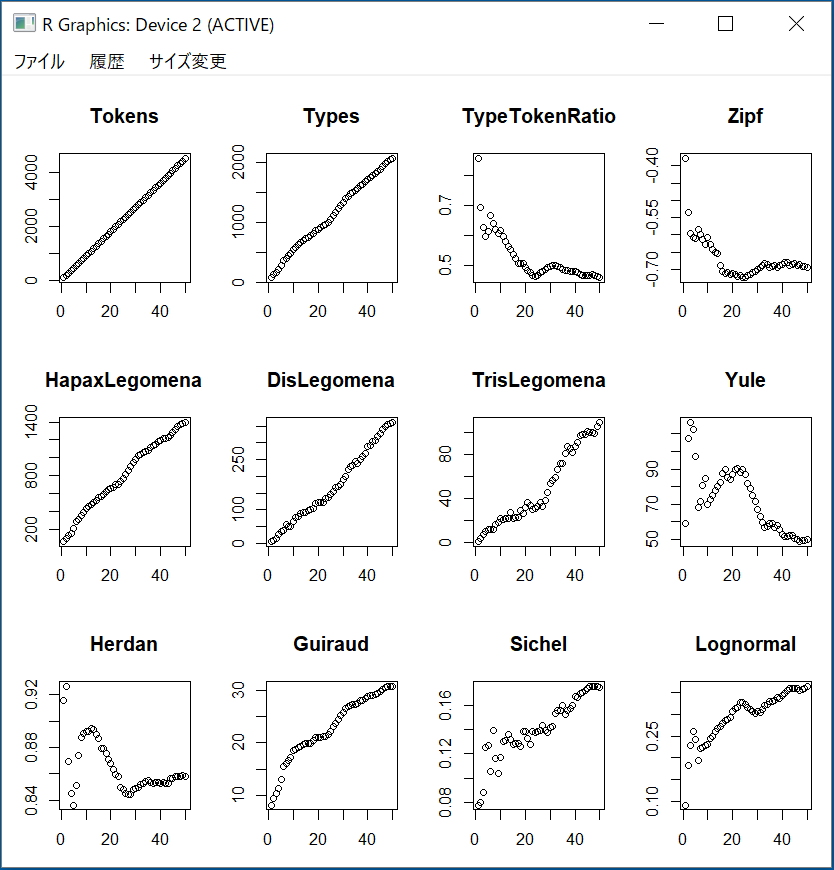
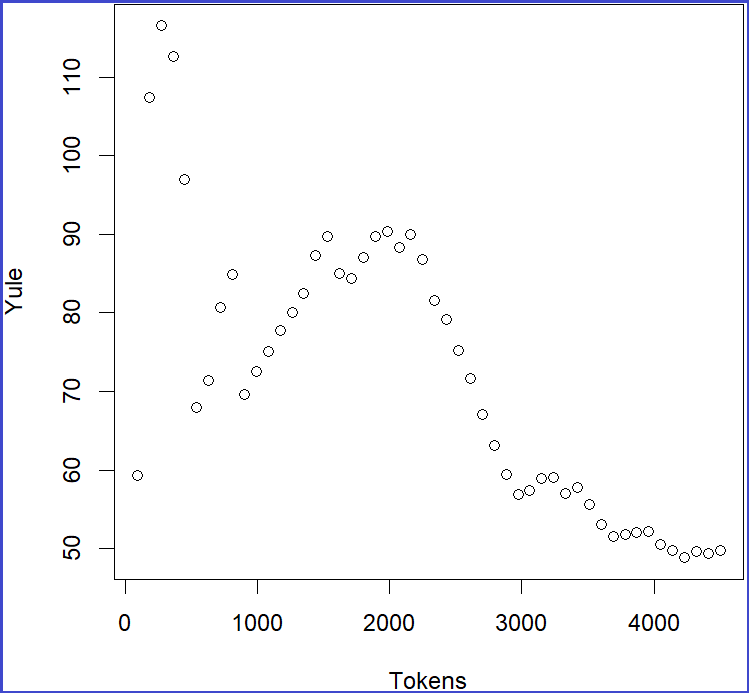
サブタブ Vocabulary Richnessでは、1つのテキストの語彙の豊富さを計算する。日本語においてはタグ記号 <>により区切られているテキストを用いる。1つのタグ付きテキストを読み込み、テキストを複数のチャンク (chunks)に区切り、チャンクを累積しながら、述べ語数、異なり語数、トークン比(TTR)、Yule の K 特性値、SichelのS値などの12種類の語彙の豊富さの指標に関する値を計算する。
Go To Top
語彙の豊富さ
サブタブ Vocabulary Richnessでは、テキストの語彙の豊富さを計算する。日本語においてはタグ記号 <>により区切られているテキストを用いる。タグ付きテキストを読み込み、テキストを複数のチャンク (chunks)に区切り、チャンクを累積しながら、述べ語数、異なり語数、トークン比(TTR)、Yule の K 特性値、SichelのS値などの12種類の語彙の豊富さの指標に関する値を計算する。 二つの選択「Input File」と「Existing File」がある。「Input File」で一つのテキストを読み込むことでその語彙の豊富さを求める。「Existing File」はMTMinRに読み込んだすべてのテキストの語彙の豊富さを求める。デフォルトは 「Existing File」である。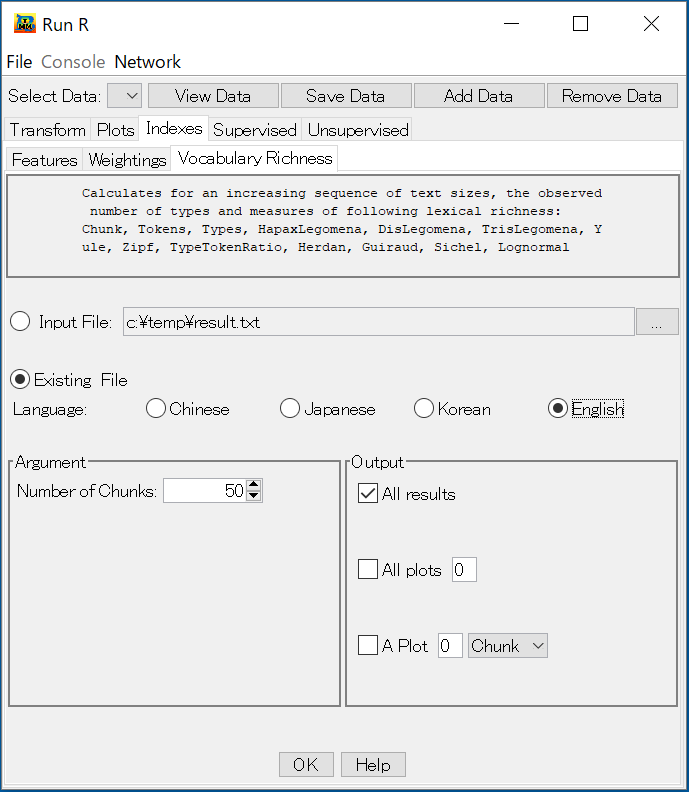
複数のテキストの語彙の豊富さを求める時、「All plot」で何番目のテキストの12種類の語彙の豊富さを表す指標のプロットを指定できる。更に、「A plot」で何番目のテキストに対して、各語彙の豊富さ指標を考察できる。
Go To Top