データ解析GUIの起動
MTMineRに同梱されているsampleフォルダの中のJapaneseの中に用意されている川端康成と三島由紀夫の作品を読み込み、読点がどの文字の後に打たれているかに関したデータを用いて説明する。 まず、次のGUI画面の設定通りにデータを集計する。
収集したデータを分析するため、メニュー[R]の中のもっともトップの項目[ProcessingOutputsInthisTab]を選択し、クリックするとデータセットの名前を指定する窓が現れる。
現れた窓にtempが入力されている。これは仮のデータ名前である。tempを削除し、各自好みの名前を指定することができる。
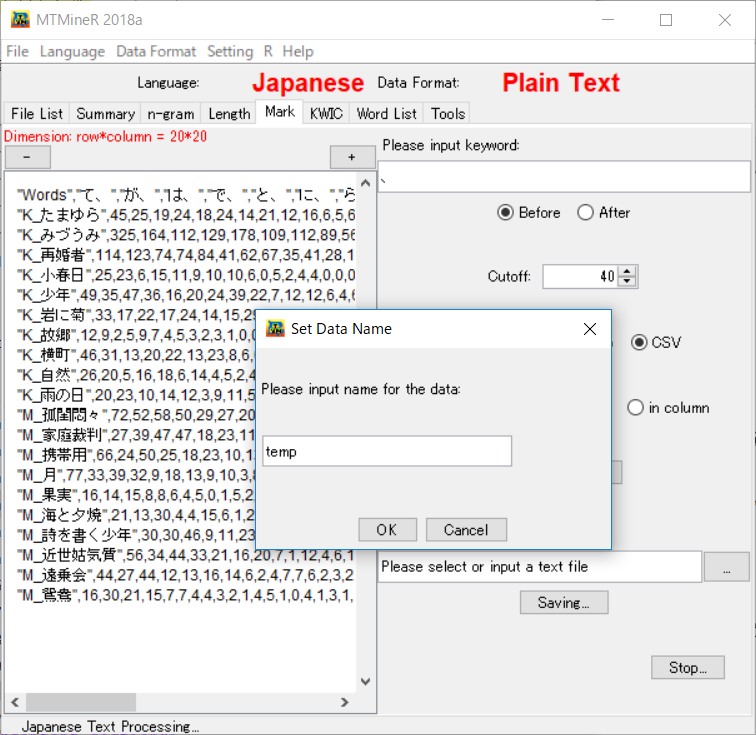
名前を指定し[OK]ボタンを押すと次のような三つの画面が同時に現れる。
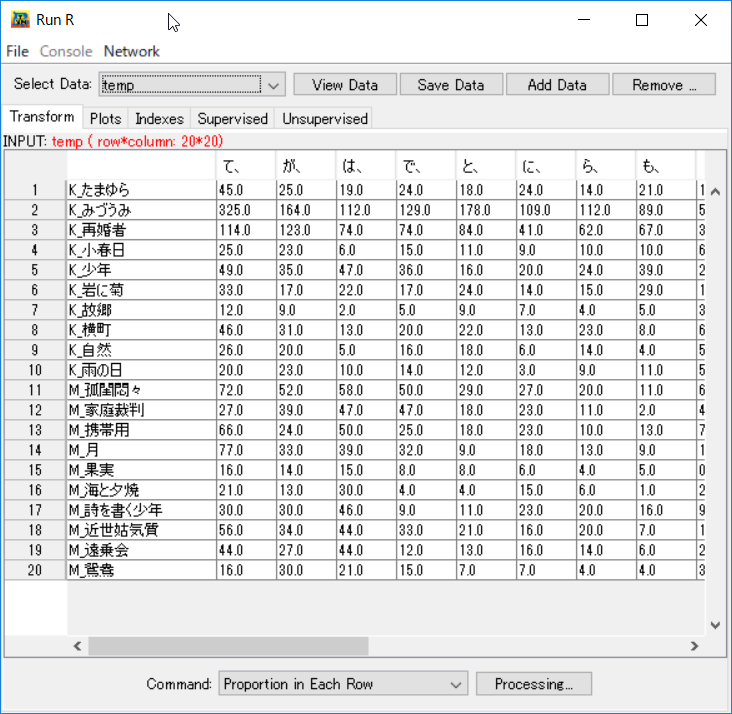
左上はRのコンソールのような役割を果たすCUI環境である。左下は、データ解析を行う際の結果出力画面である。右の画面はデータをメニュー操作で分析を行うRunRというGUIである。メニューに用意されているデータ処理・分析は、ここのメニュー操作で行うことが出来る。データ処理タブは 5 つ(Transform、Plots、Indexes、 Supervised、 Unsupervised)が用意されている。
データ変換
タブ Transformには、行の総和を基準とした相対頻度(Proportion in Each Row)、列の総和を基準とした相対頻度(Proportion in Each Column)、列を基準とした標準化(Normlization)、データ行列の転置(Transpose)の機能が用意されている。
これらの変換する項目は、画面の下部の Commandの右にリストアップされている。下向きの▼を 押して選択する。
ProportioninEachCoulum を選択し、ボタン[Processing]を押すと変換されたデータの名前を知らすメッセージボックスが開かれる。データの名前は元の名前に[.tra]が追加されていることに注意してほしい。
変換されたデータの名前は、元のデータの名前に.traが付けられる。メッセージボックス上の[OK]を押すとメッセージボックスが消される。変換されたデータを用いて分析を行うた めには RunR上の Selectdataから変換したデータを読み込むことが必要である。